La era de la IA centralizada ha muerto. Amazon AWS acaba de detonar una revolución en el silicio con el lanzamiento de los chips Inferentia 3, diseñados específicamente para el Edge Computing en América Latina. Ya no se trata de enviar datos a servidores remotos en Virginia o Irlanda; ahora, la inteligencia se procesa en el corazón de nuestras ciudades, eliminando la latencia y democratizando el acceso a modelos de lenguaje y visión computacional de alto rendimiento.
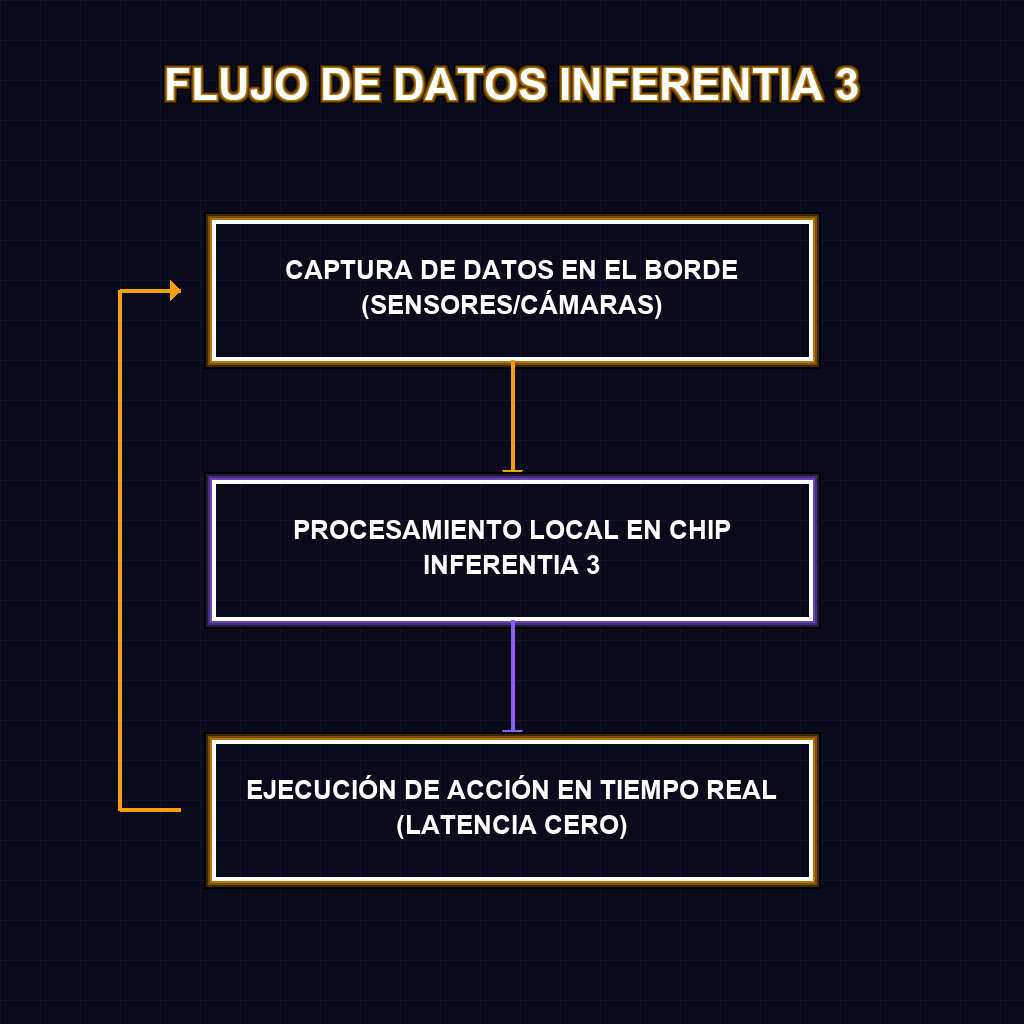
✦ ARQUITECTURA DE INFERENCIA DISTRIBUIDA
Análisis del Acontecimiento y Contexto Tecnológico
Técnicamente, el despliegue de Inferentia 3 representa un salto cuántico en la eficiencia de la inferencia. Mientras que las GPUs tradicionales son potentes pero costosas y energéticamente ineficientes para el borde, estos chips están optimizados para maximizar el rendimiento por vatio. Al integrar nodos locales en ciudades clave de LATAM, AWS está implementando una arquitectura de computación distribuida que permite que el procesamiento de tensores ocurra a milisegundos de la fuente de datos. Esto es crítico para aplicaciones donde un retraso de 100ms es la diferencia entre el éxito y el fracaso operativo.
A largo plazo, estamos presenciando la transición hacia ciudades neuronales. La capacidad de ejecutar modelos masivos en el borde sin depender de una conexión constante a la nube central rompe la dependencia de la infraestructura de red inestable de la región. Esto permitirá que el análisis de video en tiempo real, la gestión autónoma de tráfico y el IoT industrial escalen de forma orgánica. Para el ecosistema empresarial, esto significa que la IA deja de ser un gasto operativo variable y prohibitivo para convertirse en una capacidad de infraestructura local, reduciendo drásticamente el costo por inferencia.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para las empresas en América Latina, este movimiento de AWS no es solo una actualización técnica, es una ventana de oportunidad estratégica. La brecha de infraestructura que históricamente nos ha dejado rezagados frente a Norteamérica y Asia se cierra al mover el poder de cómputo directamente a nuestras calles y fábricas.
- Optimización de OpEx: Reducción masiva de costos de transferencia de datos y consumo de API de nube centralizada.
- Soberanía de Datos: Capacidad de procesar información sensible localmente, facilitando el cumplimiento de normativas de privacidad regionales.
- Escalabilidad Urbana: Implementación de soluciones de Smart Cities que funcionan incluso con intermitencias en la conectividad global.
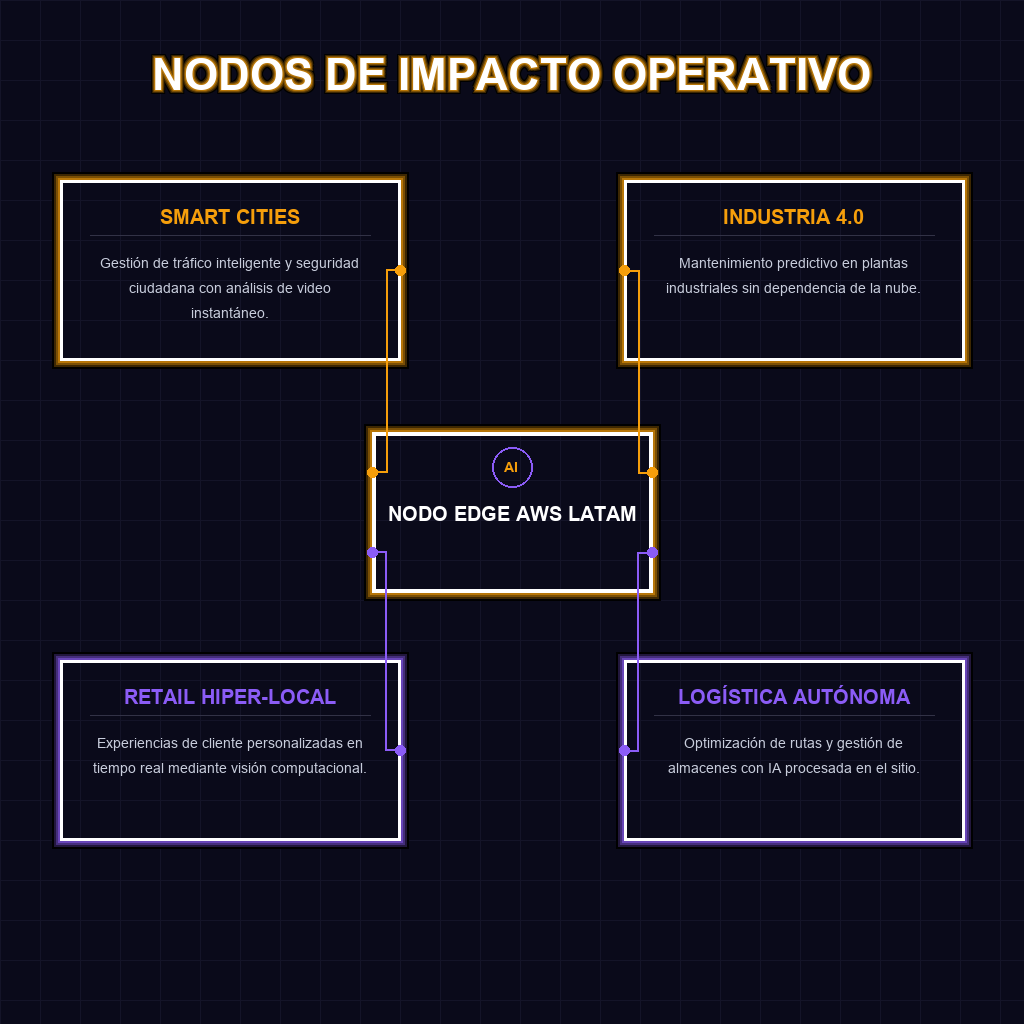
✦ ECOSISTEMA DE EDGE AI EN LATAM
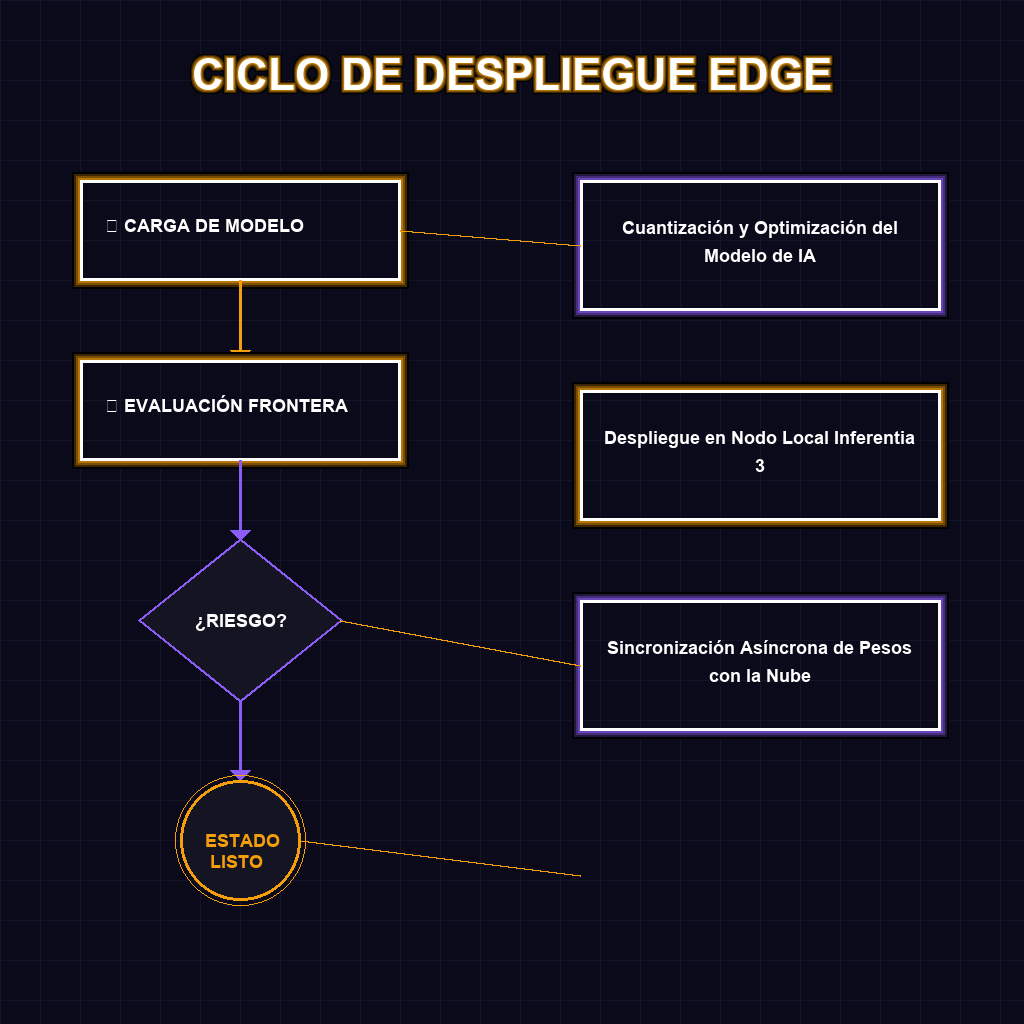
✦ RUTA DE IMPLEMENTACIÓN TÉCNICA
Preguntas Frecuentes
✦ ¿Qué es exactamente el Edge Computing y por qué importa ahora?
El Edge Computing consiste en procesar los datos lo más cerca posible de donde se generan (en el ‘borde’ de la red), en lugar de enviarlos a un centro de datos remoto. Importa ahora porque los modelos de IA se han vuelto tan grandes y demandantes que la latencia de la red se ha convertido en el principal cuello de botella para aplicaciones en tiempo real.
✦ ¿En qué se diferencia Inferentia 3 de una GPU convencional de NVIDIA?
Mientras que las GPUs son versátiles y excelentes para el entrenamiento de modelos, los chips Inferentia 3 están diseñados exclusivamente para la inferencia (la ejecución del modelo ya entrenado). Esto los hace mucho más eficientes en consumo energético y más económicos de operar a escala masiva en entornos urbanos.
✦ ¿Cómo beneficia esto a una startup de IA en América Latina?
Permite que las startups reduzcan sus costos operativos (OpEx) al no tener que pagar transferencias de datos masivas hacia la nube y ofrece un rendimiento superior para sus clientes finales, permitiendo crear productos que funcionan en tiempo real, algo que antes era técnicamente inviable o financieramente insostenible en la región.
Fuente original de referencia: AWS Blog
📥 Descarga el Recurso Gratuito
Accede a nuestro catálogo de agentes de IA empresariales autónomos, diseñados con arquitecturas de runtime robustas.

