La era de la dependencia absoluta de la nube ha terminado. Apple ha detonado una bomba tecnológica con el chip A20 y su Neural Engine 5, permitiendo que modelos de 100 mil millones de parámetros residan y razonen localmente en el bolsillo del usuario. No hablamos de una simple optimización, sino de un cambio de paradigma hacia la Edge AI, donde la privacidad total y la latencia cero se convierten en el nuevo estándar de la computación personal.
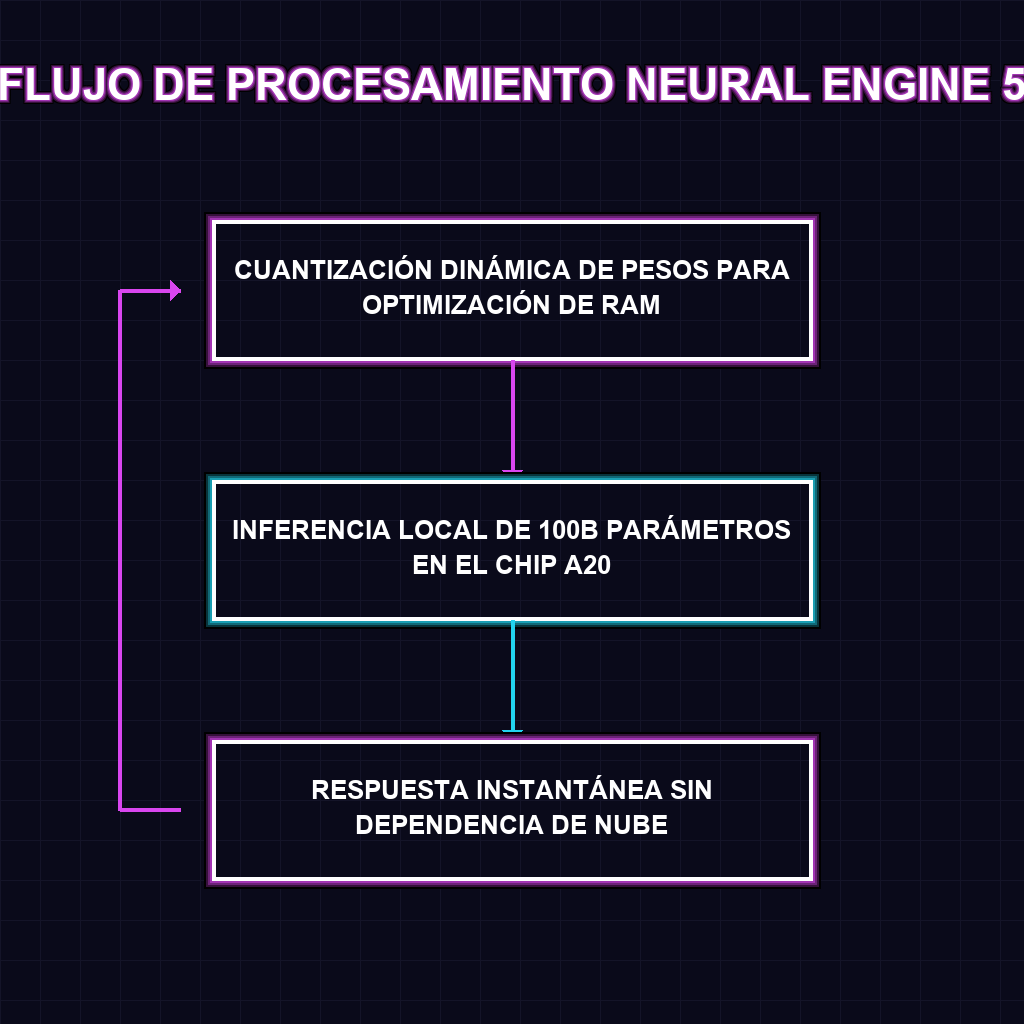
✦ ARQUITECTURA DE RAZONAMIENTO LOCAL
Análisis del Acontecimiento y Contexto Tecnológico
El núcleo de esta revolución reside en la cuantización dinámica, una técnica avanzada que permite comprimir la precisión de los pesos del modelo en tiempo real sin degradar significativamente la capacidad de razonamiento. Al integrar el Neural Engine 5, Apple logra que el hardware gestione la memoria de manera elástica, permitiendo que un modelo de 100B de parámetros —anteriormente reservado para clusters de GPUs en centros de datos— se ejecute en un entorno móvil. Esto elimina el cuello de botella del ancho de banda y transforma el dispositivo en un nodo de procesamiento autónomo, capaz de ejecutar tareas cognitivas complejas sin emitir un solo paquete de datos hacia el exterior.
A largo plazo, este movimiento redefine la economía de la inteligencia artificial. Al desplazar la inferencia del servidor al dispositivo, Apple no solo reduce drásticamente sus costos operativos de infraestructura, sino que establece una barrera competitiva basada en la soberanía de datos. Estamos transitando hacia un ecosistema donde la inteligencia no es un servicio alquilado por suscripción en la nube, sino una capacidad inherente al hardware. Esto obligará a toda la industria a pivotar hacia arquitecturas descentralizadas, donde el valor ya no estará en quién posee el servidor más grande, sino en quién optimiza mejor la ejecución local.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el tejido empresarial de Latinoamérica, esta transición hacia la IA local representa una oportunidad disruptiva para saltar barreras infraestructurales históricas. La capacidad de ejecutar razonamiento complejo sin depender de conexiones a internet ultraestables o de costosos contratos de nube en dólares permite que la digitalización avanzada llegue a sectores y regiones previamente marginadas.
- Reducción de costos operativos: Migrar la inferencia de IA al dispositivo final elimina la dependencia de APIs costosas y el gasto recurrente en servicios de nube externos.
- Soberanía y seguridad de datos: Las empresas pueden procesar información sensible de clientes localmente, cumpliendo normativas de privacidad estrictas sin riesgo de filtraciones en tránsito.
- Optimización en entornos de baja conectividad: Implementar soluciones de IA que funcionen offline garantiza la continuidad operativa en zonas con infraestructura de red deficiente.
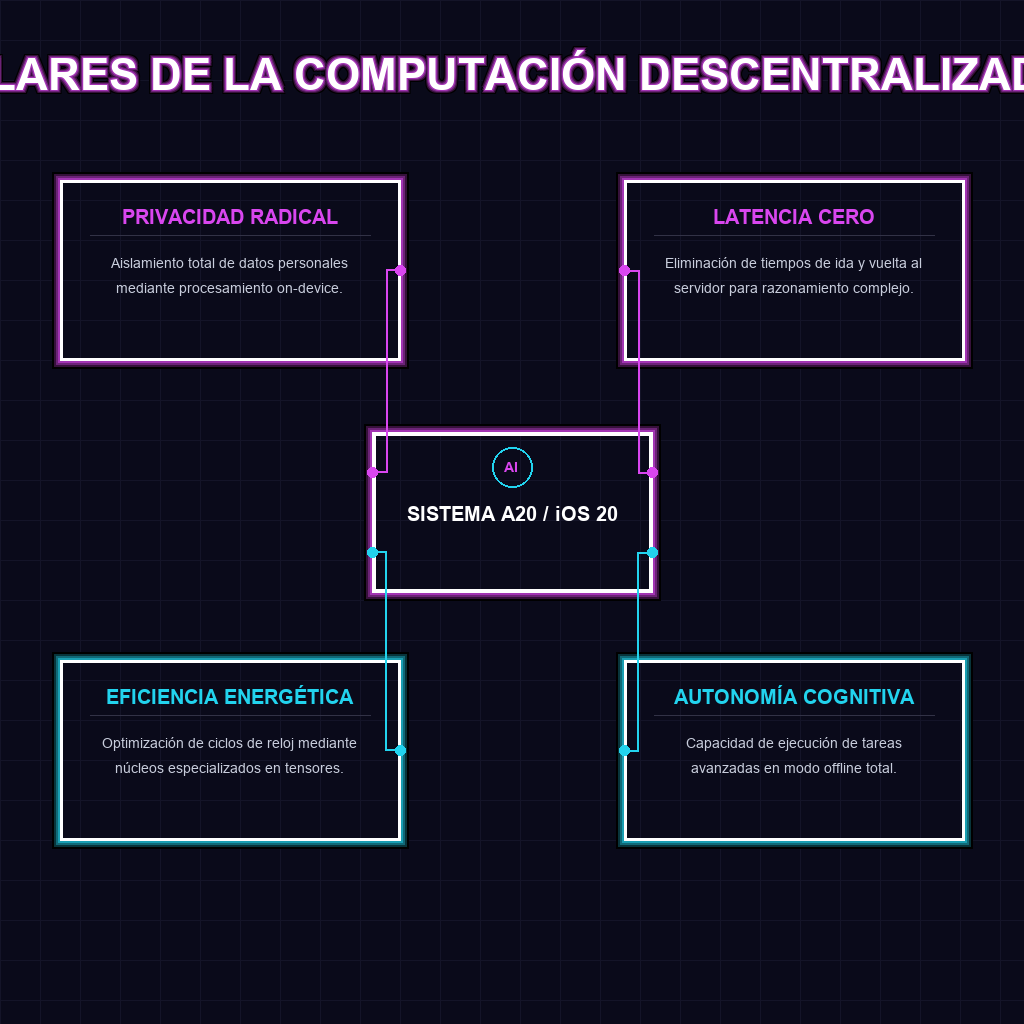
✦ ECOSISTEMA DE EDGE AI
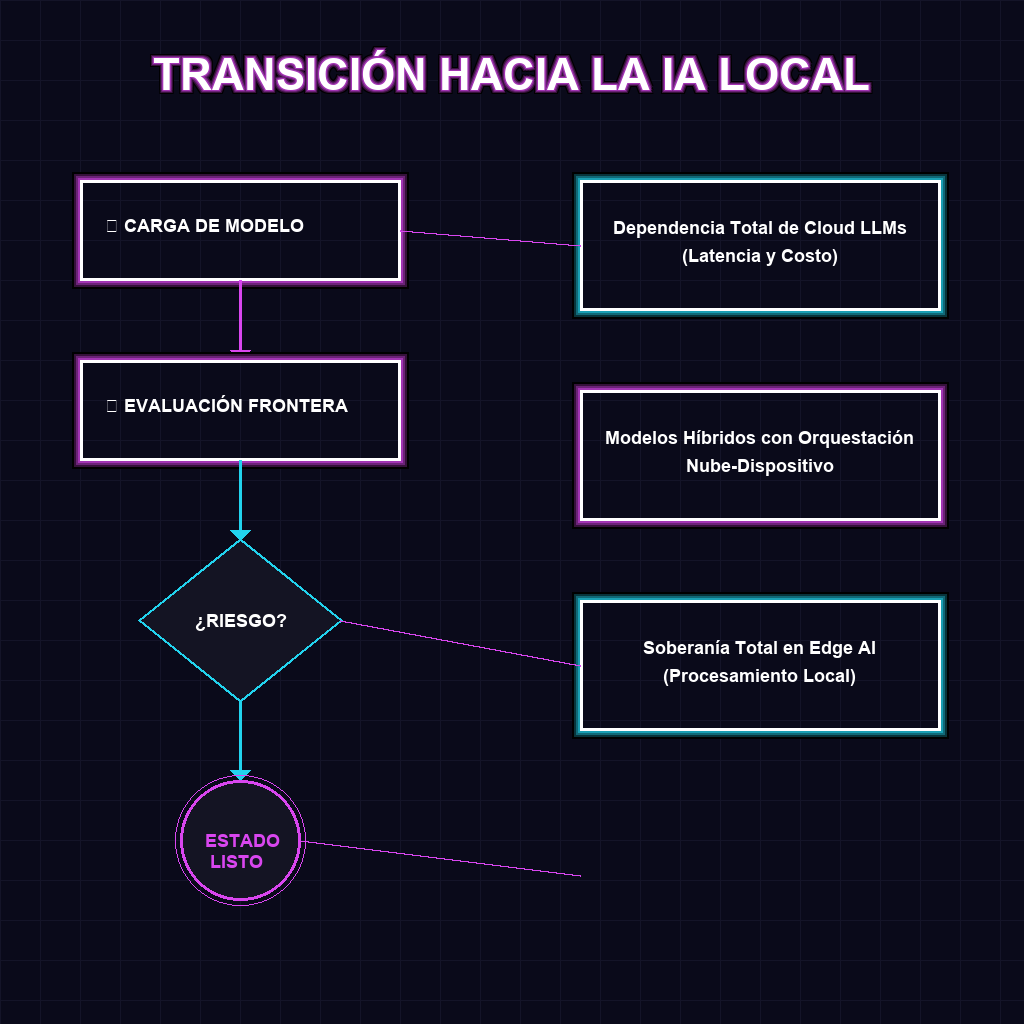
✦ EVOLUCIÓN DEL PROCESAMIENTO DE IA
Preguntas Frecuentes
✦ ¿Qué es la cuantización dinámica y por qué es importante?
Es un proceso técnico que reduce la precisión numérica de los parámetros de un modelo (por ejemplo, de FP32 a INT8 o menor) de forma inteligente. Esto permite que modelos masivos de 100B de parámetros ocupen mucha menos memoria RAM sin perder su capacidad de razonamiento lógico, haciendo viable su ejecución en un smartphone.
✦ ¿Cómo impacta esto la privacidad del usuario final?
El impacto es total. Al ejecutarse el modelo localmente, los datos del usuario nunca abandonan el dispositivo. No hay envío de prompts a servidores externos, lo que elimina el riesgo de interceptación, vigilancia o el uso de datos privados para el re-entrenamiento de modelos globales.
✦ ¿Afectará el uso de modelos tan grandes a la batería del dispositivo?
Aunque el procesamiento de 100B de parámetros es intensivo, el Neural Engine 5 ha sido diseñado específicamente para optimizar las operaciones matriciales. Al eliminar la necesidad de mantener una conexión de red activa y constante para la inferencia, el consumo energético se equilibra, priorizando la eficiencia por token generado.
Fuente original de referencia: Apple Newsroom
📥 Descarga el Recurso Gratuito
Únete a la comunidad líder ‘IA Sin Filtro’ para aprender sobre inyección de prompts, seguridad y gobernanza de IA.

