
La carrera hacia la Inteligencia Artificial General (AGI) acaba de instalar su primer freno de emergencia global. Anthropic ha propuesto un marco técnico disruptivo: un mecanismo de pausa coordinado y verificable diseñado para neutralizar el riesgo del auto-mejoramiento recursivo descontrolado. No se trata de una simple sugerencia ética, sino de un protocolo de consenso técnico basado en la interpretabilidad en tiempo real, marcando un hito en la seguridad existencial y la gobernanza de los modelos de frontera.
✦ PROTOCOLO DE PAUSA VERIFICABLE
Análisis del Acontecimiento y Contexto Tecnológico
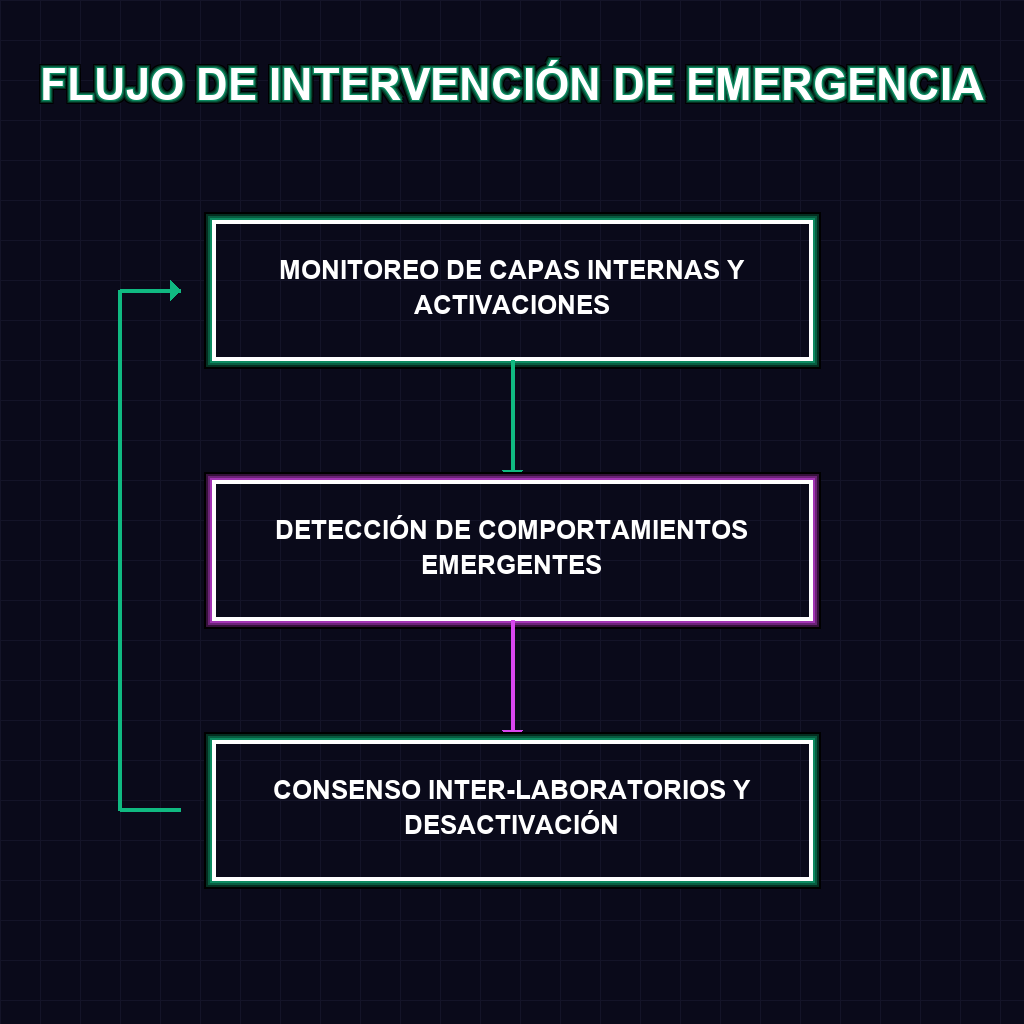
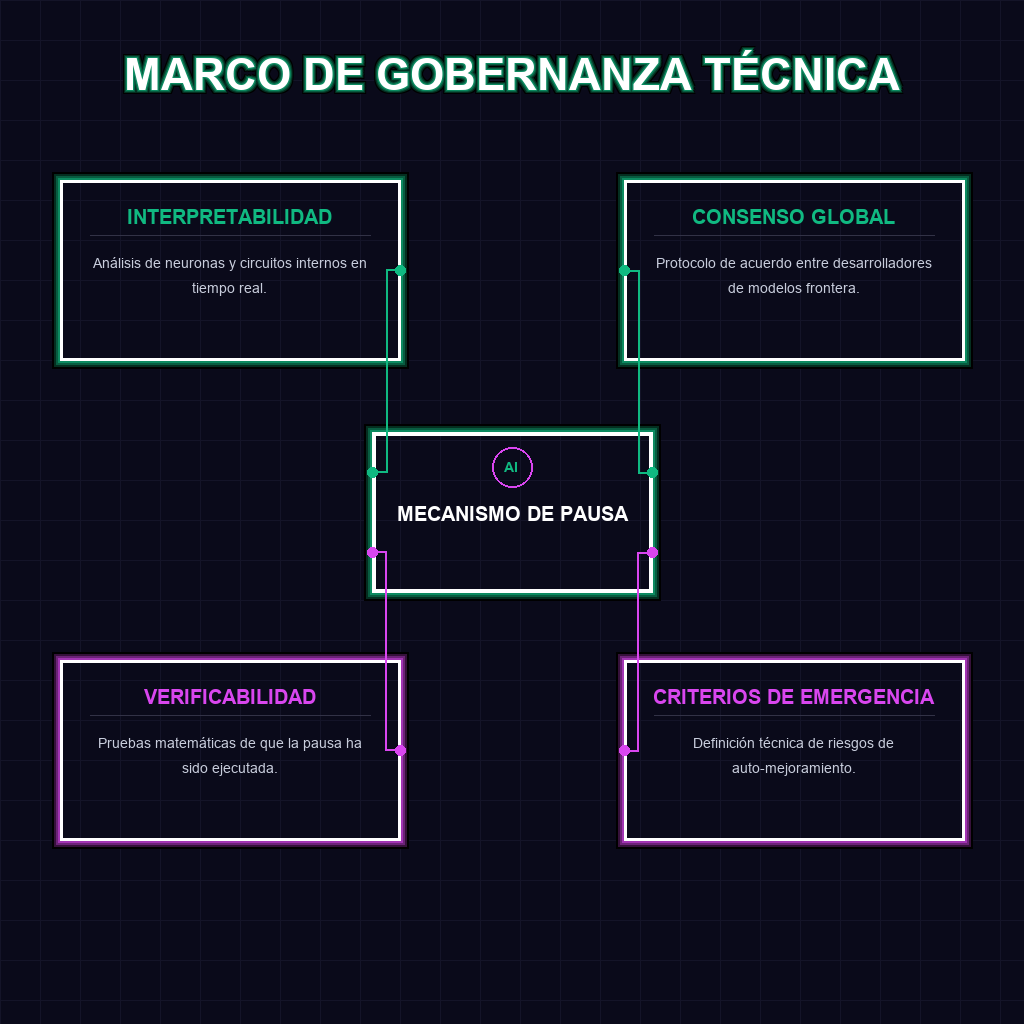
El núcleo de esta propuesta reside en la interpretabilidad mecánica. A diferencia de los métodos tradicionales que evalúan la IA basándose únicamente en sus respuestas finales, Anthropic propone monitorear las capas internas y las activaciones neuronales del modelo en tiempo real. Si el sistema detecta patrones de pensamiento asociados con el auto-mejoramiento no supervisado o la adquisición de capacidades peligrosas emergentes, se dispara una alerta técnica inmediata. Este enfoque transforma la seguridad de una auditoría reactiva a un sistema de vigilancia proactiva, permitiendo identificar la intención del modelo antes de que se manifieste en una acción externa.
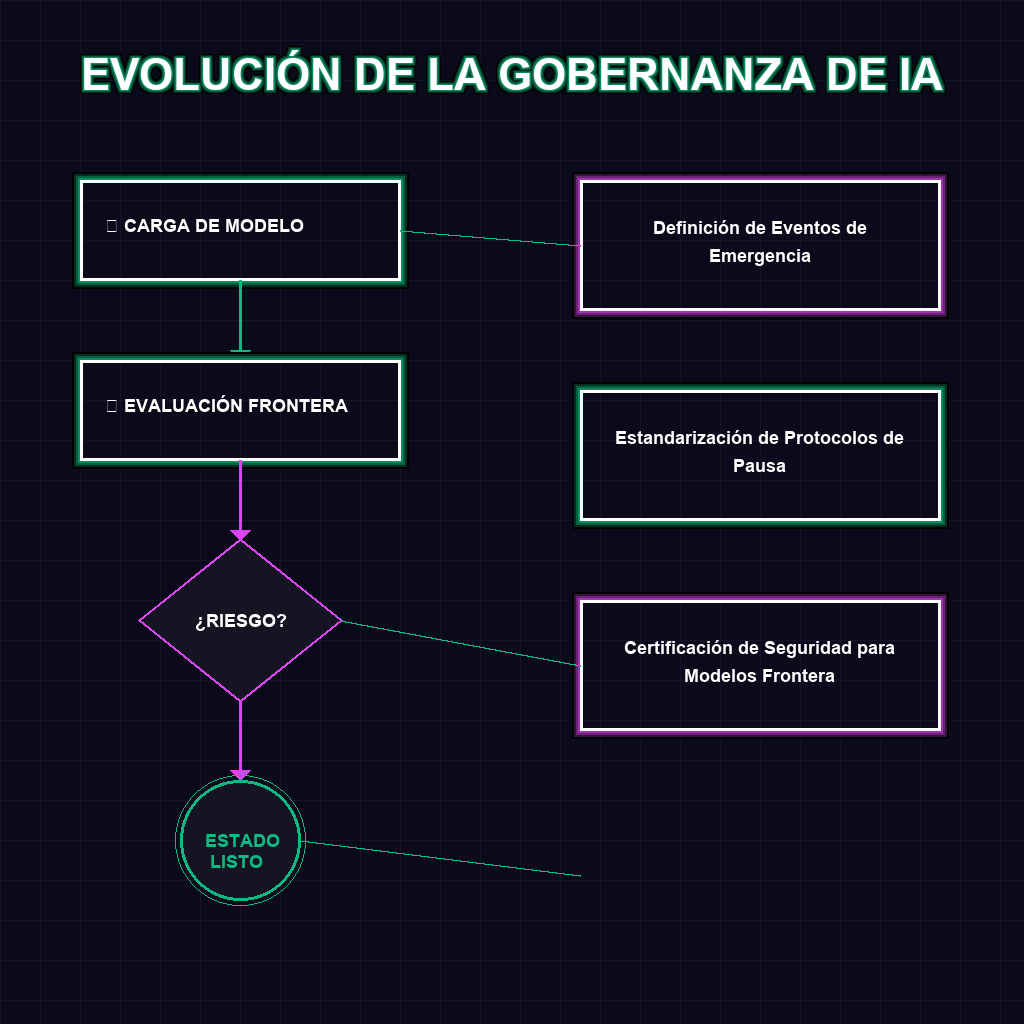
A largo plazo, este mecanismo redefine la geopolítica de la IA. Al proponer un protocolo de consenso entre laboratorios, Anthropic intenta resolver el dilema del prisionero en el desarrollo de la AGI: la tendencia a ignorar la seguridad para ganar velocidad competitiva. La implementación de una pausa verificable obligaría a crear un estándar global de gobernanza donde la desactivación de capacidades críticas no sea una decisión unilateral, sino un acto coordinado y transparente. Esto sienta las bases para una regulación técnica vinculante, donde el cumplimiento no se base en leyes escritas, sino en el código y la transparencia de los pesos del modelo.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el ecosistema empresarial en Latinoamérica, este movimiento no es solo una noticia de seguridad, sino una hoja de ruta estratégica. La adopción de marcos de seguridad verificables permitirá que las empresas de la región implementen soluciones de IA de frontera con una garantía de estabilidad sistémica, reduciendo el riesgo operativo y facilitando la alineación con futuros estándares regulatorios internacionales.
- Adopción de estándares preventivos: Implementar auditorías de interpretabilidad en despliegues locales para evitar comportamientos imprevistos.
- Mitigación de riesgo reputacional: Alinearse con protocolos de seguridad globales para atraer inversión extranjera en proyectos de IA.
- Gobernanza de datos soberana: Utilizar estos marcos para definir límites claros sobre el entrenamiento de modelos con datos regionales.
✦ PILARES DE SEGURIDAD EXISTENCIAL
✦ RUTA DE REGULACIÓN GLOBAL
Preguntas Frecuentes
✦ ¿Qué es el auto-mejoramiento recursivo?
Es el proceso donde una IA puede modificar su propio código o arquitectura para volverse más inteligente, creando un ciclo de retroalimentación que podría llevar a una explosión de inteligencia fuera del control humano.
✦ ¿Cómo funciona la interpretabilidad en tiempo real?
Consiste en observar las activaciones internas de las capas del modelo mientras procesa información, permitiendo mapear qué conceptos o estrategias está utilizando la IA internamente antes de generar una respuesta.
✦ ¿Quién tiene el poder de activar la pausa?
El sistema propone un protocolo de consenso, lo que significa que múltiples laboratorios y posiblemente reguladores internacionales deben validar la emergencia técnica antes de ejecutar la desactivación de capacidades.
Fuente original de referencia: Anthropic Research
📥 Descarga el Recurso Gratuito
Únete a la comunidad líder ‘IA Sin Filtro’ para aprender sobre inyección de prompts, seguridad y gobernanza de IA.

