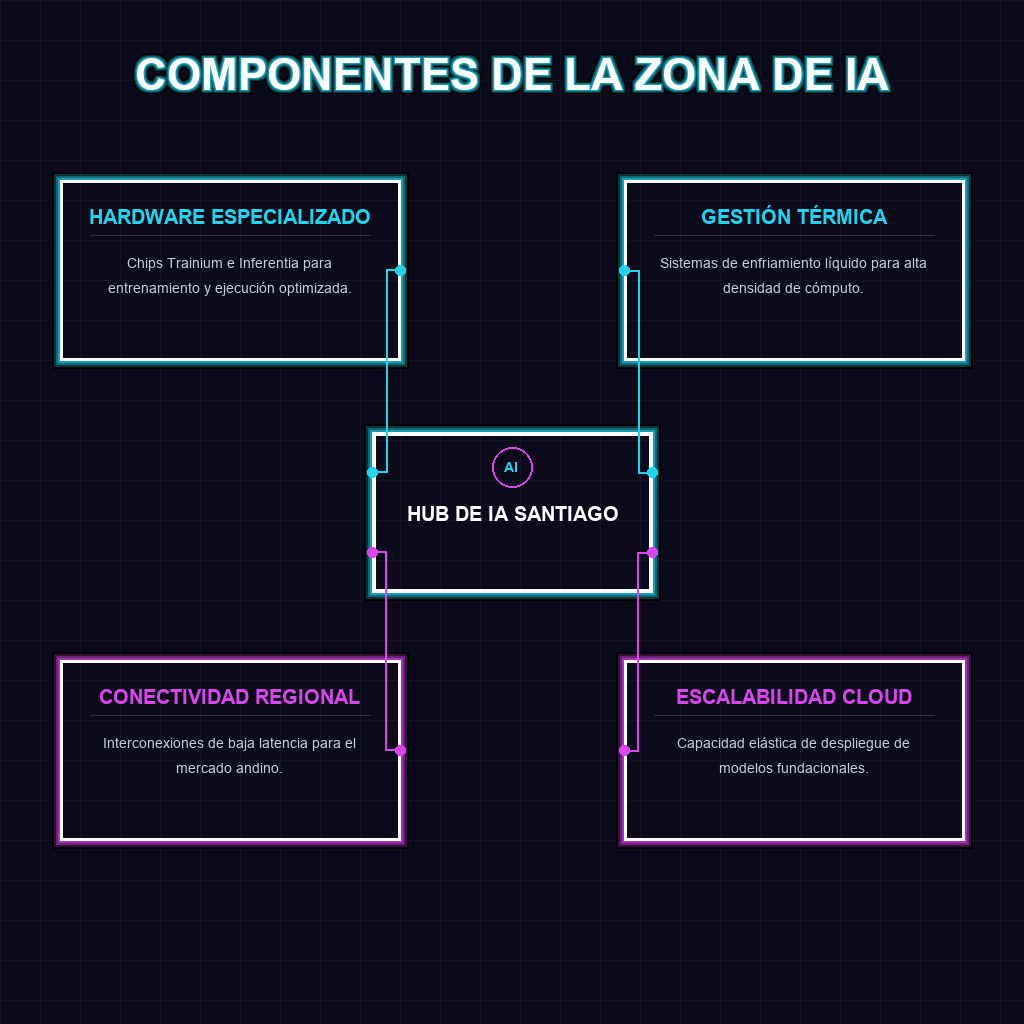
Santiago se posiciona como el nuevo nodo neurálgico de la inteligencia artificial en el Cono Sur. Con la inauguración de la Zona de Inferencia de AWS, Chile deja de ser un mero consumidor de nube para convertirse en un centro de procesamiento de alta velocidad. Esta infraestructura, potenciada por chips Trainium e Inferentia, redefine la latencia y la eficiencia operativa, permitiendo que el ecosistema empresarial andino despliegue modelos de IA generativa con una respuesta casi instantánea y costos optimizados.
✦ ARQUITECTURA DE INFERENCIA AWS
Análisis del Acontecimiento y Contexto Tecnológico
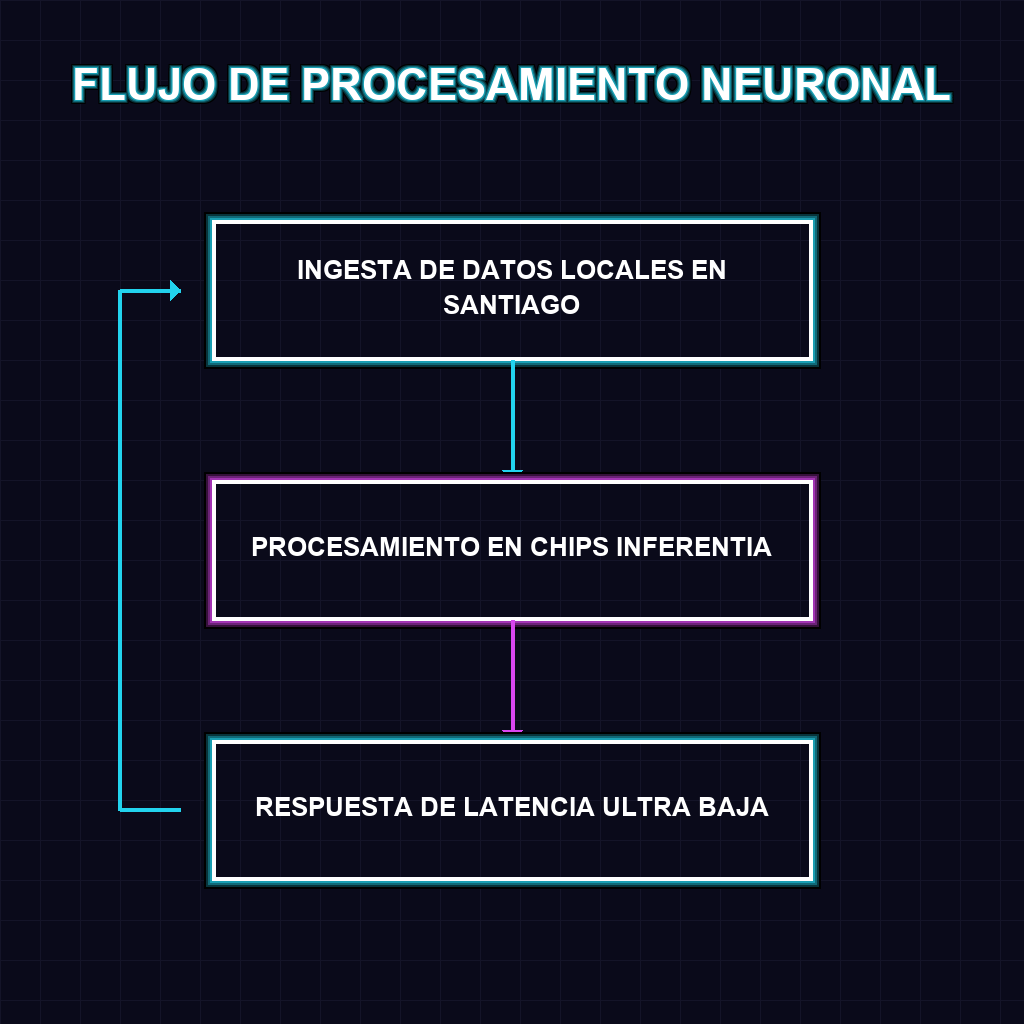
La implementación de una zona de inferencia dedicada representa un salto cualitativo en la arquitectura de nube regional. A diferencia de las regiones estándar, este despliegue se enfoca en la fase de ejecución del modelo, donde el chip Inferentia reduce drásticamente el costo por inferencia y la latencia de respuesta. La integración de Trainium permite, además, que el ajuste fino (fine-tuning) de modelos masivos ocurra más cerca del dato, eliminando los cuellos de botella transoceánicos y optimizando el flujo de tokens en aplicaciones de tiempo real que requieren una precisión quirúrgica.
A largo plazo, este movimiento de AWS actúa como un catalizador de soberanía tecnológica y atracción de capital. Al reducir la fricción técnica, Chile se vuelve el destino lógico para startups de IA que requieren rendimiento extremo sin depender de servidores en Virginia o Irlanda. El uso de enfriamiento líquido avanzado no es solo una mejora técnica, sino una declaración de sostenibilidad y escalabilidad, preparando el terreno para la llegada de modelos de lenguaje aún más densos que demanden una densidad térmica imposible de gestionar con sistemas de aire tradicionales.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para las empresas de América Latina, esta infraestructura rompe la barrera de la distancia física, transformando la IA de una herramienta experimental a una ventaja competitiva operativa. La capacidad de procesar datos localmente permite una integración más profunda con procesos industriales y financieros en tiempo real.
- Optimización de costos operativos: Migrar la inferencia a chips especializados reduce la dependencia de GPUs costosas y escasas.
- Despliegue de IA en tiempo real: La latencia ultra baja habilita aplicaciones de trading, salud y logística con respuestas en milisegundos.
- Cumplimiento y Gobernanza: Facilita la gestión de datos sensibles al mantener el flujo de inferencia dentro de fronteras geográficas más controladas.
✦ ECOSISTEMA TÉCNICO SANTIAGO
✦ RUTA DE IMPLEMENTACIÓN EMPRESARIAL
Preguntas Frecuentes
✦ ¿Qué es exactamente una Zona de Inferencia?
Es una infraestructura de nube especializada diseñada específicamente para ejecutar modelos de IA ya entrenados. A diferencia de una región general, optimiza la velocidad de respuesta y reduce los costos operativos al utilizar hardware dedicado a la inferencia.
✦ ¿En qué se diferencian los chips Trainium e Inferentia?
Trainium está optimizado para el entrenamiento de modelos y el ajuste fino (fine-tuning), mientras que Inferentia está diseñado exclusivamente para la inferencia, es decir, para generar respuestas rápidas a partir de modelos ya existentes con un consumo energético menor.
✦ ¿Por qué es crítico el enfriamiento líquido en este centro?
Los chips de IA generan una cantidad masiva de calor debido a la densidad de sus cálculos. El enfriamiento líquido es significativamente más eficiente que el aire, permitiendo concentrar más potencia de cómputo en menos espacio sin riesgo de degradación térmica o fallos de hardware.
Fuente original de referencia: AWS Press
📥 Descarga el Recurso Gratuito
Accede a nuestro catálogo de agentes de IA empresariales autónomos, diseñados con arquitecturas de runtime robustas.

