El ecosistema tech latinoamericano acaba de encender sus motores de hiper-velocidad. Amazon Web Services ha desplegado la disponibilidad general de sus instancias Trainium3 en la región de São Paulo (sa-east-1), diseñadas exclusivamente para devorar inferencia de modelos de gran escala. Esta infraestructura de vanguardia promete una cirugía de costos del 40% y una optimización energética del 60%, democratizando el acceso al cómputo de alto rendimiento y borrando de un tajo la brecha de latencia para las corporaciones LATAM.
✦ ARQUITECTURA DE INFERENCIA TRAINIUM3
Análisis del Acontecimiento y Contexto Tecnológico
El despliegue del silicio Trainium3 en sa-east-1 no es una simple actualización de catálogo; es una reconfiguración brutal de la topología de red para la inteligencia artificial en la región. La inferencia, el momento crítico donde el modelo genera predicciones en tiempo real, exige un ancho de banda y una proximidad física que las arquitecturas legacy simplemente no pueden sostener. Al aterrizar este acelerador de última generación en territorio brasileño, AWS elimina los saltos de red intercontinentales que asfixiaban la velocidad de respuesta. Esto se traduce en interacciones conversacionales y cálculos financieros algorítmicos que se ejecutan en milisegundos, estableciendo un nuevo estándar operativo donde la latencia extrema es una variable controlada y dominada por las empresas locales.
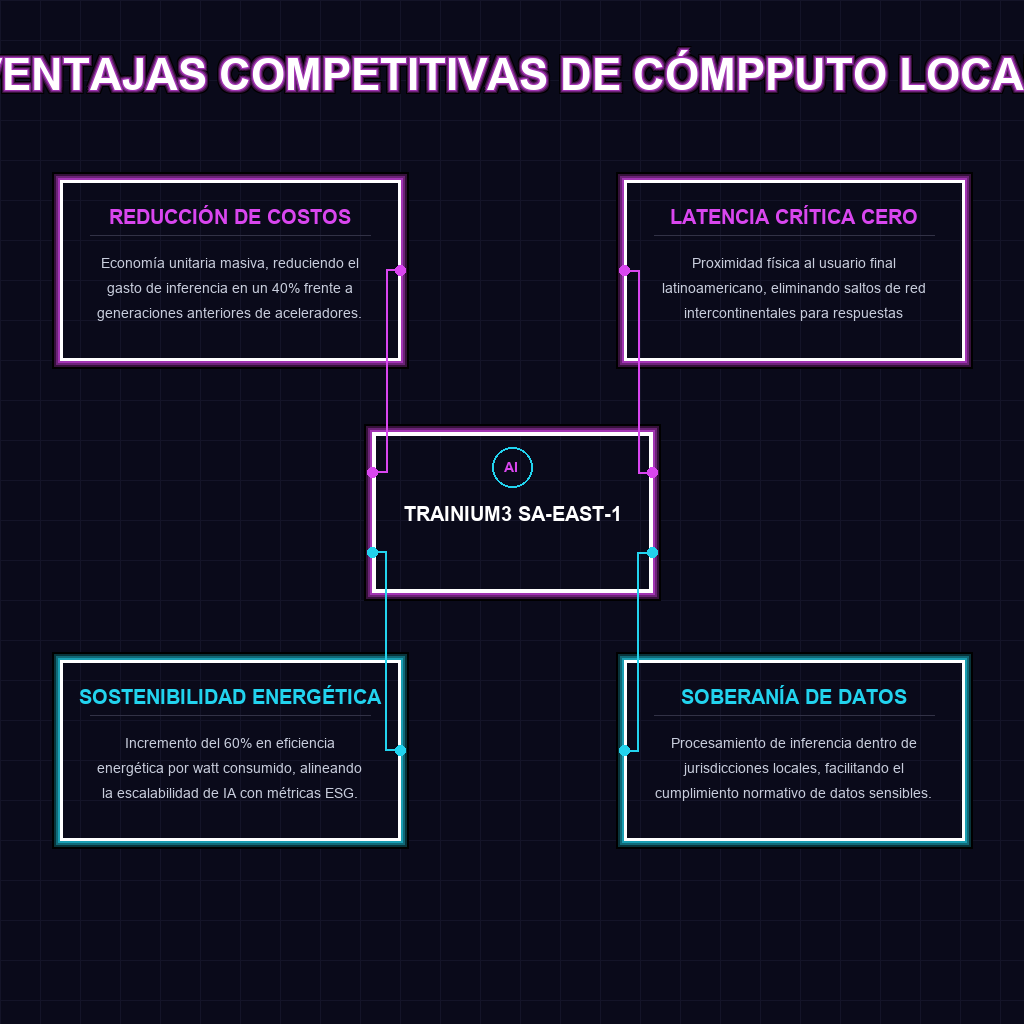
A largo plazo, esta movida de infraestructura reescribe las reglas del juego competitivo a nivel global. La reducción del 40% en costos de inferencia combinada con el incremento del 60% en eficiencia energética transforma la economía unitaria de los productos de IA. Las startups y corporaciones latinoamericanas pueden escalar sus operaciones de modelos fundacionales y agentes autónomos sin ver evaporarse sus márgenes de ganancia en facturas de cómputo. El programa de créditos para desarrolladores locales actúa como un catalizador de adopción temprana, inyectando capital de infraestructura directamente en el ecosistema. LATAM deja de ser un consumidor pasivo de tecnología foránea para convertirse en un laboratorio de aplicaciones de IA de alto rendimiento, compitiendo de tú a tú con los polos de innovación de Norteamérica y Europa en eficiencia y agilidad.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el tejido empresarial de LATAM, la disponibilidad del Trainium3 en la región es el equivalente a recibir las llaves de la nave nodriza. Históricamente, la barrera de entrada para correr modelos de lenguaje masivos o sistemas de visión computacional de frontera estaba limitada por la logística de transferencia de datos y los costos prohibitivos del cómputo en la nube. Este aterrizaje de hardware de vanguardia democratiza el acceso, permitiendo que desde un neobanco en Colombia hasta una agritech en Argentina puedan procesar inferencias pesadas en tiempo real, sin el subsidio de latencias transoceánicas. Es la oportunidad de oro para construir productos nativos de IA con una infraestructura que antes solo estaba al alcance de las mega-corporaciones del primer mundo.
- Migración inmediata de cargas de inferencia: Redirigir el tráfico de modelos de lenguaje y predicción desde regiones lejanas hacia sa-east-1 para capitalizar la reducción de latencia y la caída del 40% en costos de operación.
- Activación de créditos de aceleración: Aprovechar el programa de créditos de AWS para startups LATAM para financiar la experimentación y el despliegue de agentes de IA conversacionales y financieros sin quemar el runway inicial.
- Diseño de arquitecturas de baja latencia: Construir aplicaciones críticas de misión (como trading algorítmico o diagnósticos médicos en tiempo real) que antes eran inviables por la distancia geográfica de los centros de datos de inferencia.
✦ VENTAJAS COMPETITIVAS DE CÓMPPUTO LOCAL
✦ RUTA DE ADOPCIÓN PARA ECOSISTEMA LATAM
Preguntas Frecuentes
✦ ¿Qué diferencia fundamental aporta Trainium3 frente a los aceleradores de inferencia anteriores?
Trainium3 introduce una microarquitectura optimizada nativamente para cargas de inferencia de modelos de gran escala. Esto se materializa en dos métricas críticas: una reducción del 40% en el costo por token procesado y un aumento del 60% en la eficiencia energética (inferencia por watt), permitiendo a las empresas escalar sus operaciones de IA de manera sostenible y rentable sin comprometer el rendimiento.
✦ ¿Por qué es estratégico que estas instancias estén en la región de São Paulo (sa-east-1)?
La localización geográfica es el factor determinante para la latencia. Al tener el hardware de inferencia en sa-east-1, los datos de usuarios latinoamericanos no necesitan viajar a servidores en Norteamérica o Europa. Esto elimina cientos de milisegundos de retraso, lo que es vital para aplicaciones de IA conversacional, asistentes financieros y trading algorítmico donde la respuesta en tiempo real es un imperativo de negocio y experiencia de usuario.
✦ ¿Cómo pueden las startups latinoamericanas acceder al programa de créditos mencionado?
AWS ha diseñado un programa de créditos específicamente estructurado para el ecosistema emergente de LATAM. Las startups que estén desarrollando aplicaciones de IA localmente pueden aplicar a través de los programas de activación de AWS para startups en la región, obteniendo acceso a capital de infraestructura que les permite experimentar, iterar y desplegar modelos sobre Trainium3 sin incurrir en altos costos iniciales de cómputo.
Fuente original de referencia: AWS News Blog
📥 Descarga el Recurso Gratuito
Únete a la comunidad líder ‘IA Sin Filtro’ para aprender sobre inyección de prompts, seguridad y gobernanza de IA.

