Google DeepMind rompe el status quo tecnológico con Gemini Ultra 2.0. Este modelo insignia no solo integra razonamiento multimodal y agentes autónomos, sino que implementa un optimizador semántico nativo para español y portugués. Con una reducción de latencia del 40% en servidores de Santiago y São Paulo, las corporaciones latinoamericanas conquistan la soberanía operativa, desplegando IA de grado empresarial sin depender de la infraestructura norteamericana.
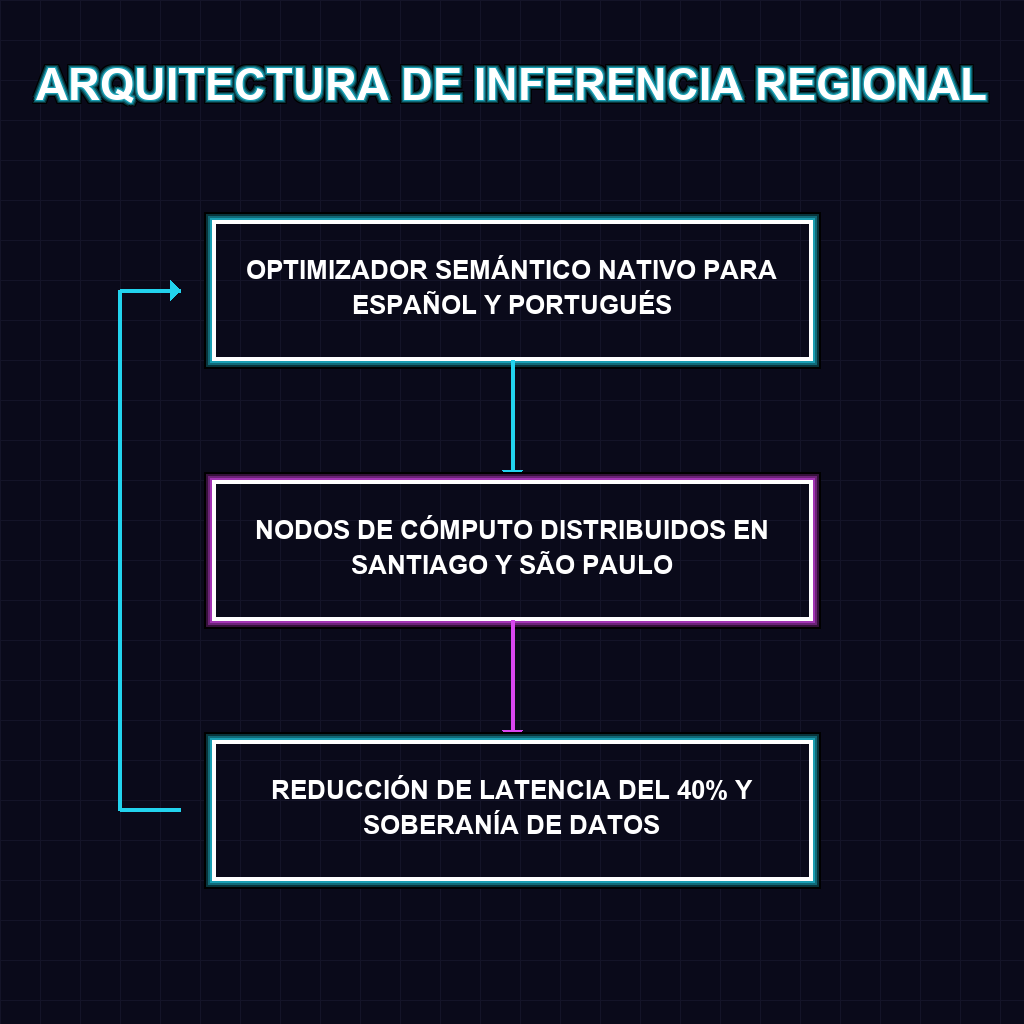
✦ ARQUITECTURA DE INFERENCIA REGIONAL
Análisis del Acontecimiento y Contexto Tecnológico
La arquitectura de Gemini Ultra 2.0 representa un salto cuántico en la ingeniería de modelos fundacionales. Al integrar razonamiento multimodal avanzado, el sistema procesa texto, audio e imagen en un espacio vectorial unificado, eliminando la degradación cognitiva típica de los modelos encadenados. Sin embargo, la verdadera innovación reside en su optimizador semántico nativo. Históricamente, el español y el portugués sufrían una penalización de inferencia al operar sobre capas de traducción intermedia basadas en tokens anglosajones. DeepMind ha reescrito las matrices de atención para procesar la morfología y sintaxis iberoamericana de forma directa. Esto, sumado a la distribución de nodos de cómputo en las regiones de Vertex AI en Santiago y São Paulo, corta el cable umbilical de los centros de datos norteamericanos, reduciendo el tiempo de respuesta en un 40% y habilitando la ejecución de agentes autónomos en tiempo real crítico.
Las implicaciones a largo plazo de este despliegue de infraestructura reconfiguran el tablero geopolítico y corporativo de la inteligencia artificial en la región. La soberanía operativa ya no es un concepto teórico; al procesar y almacenar la inferencia dentro de las fronteras de LATAM, las empresas se protegen contra interrupciones por disputas jurisdiccionales extranjeras y garantizan el cumplimiento normativo local de protección de datos. En el corto plazo, los sectores financiero y retail experimentarán una compresión dramática en sus costos operativos de inferencia, acelerando la adopción de agentes de IA que pueden operar de forma autónoma en la gestión de riesgos, atención al cliente y logística de cadena de suministro. Las organizaciones que no migren sus cargas de trabajo a estos nodos regionales enfrentarán una desventaja competitiva letal, atrapados en la latencia de la era analógica.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para los líderes tecnológicos en Latinoamérica, Gemini Ultra 2.0 no es simplemente una actualización de software; es la llave maestra para desbloquear la autonomía estratégica. La dependencia histórica de centros de datos foráneos encarecía la innovación y exponía las operaciones a vulnerabilidades de red y regulaciones ajenas. Este hito permite a las empresas de la región construir ecosistemas de IA empresarial con latencia de microsegundos, protegiendo la propiedad intelectual dentro de nuestras fronteras y reduciendo drásticamente los costos de cómputo. Es el momento de escalar las operaciones autónomas sin las cadenas del hemisferio norte.
- Migrar inmediatamente las cargas de trabajo de inferencia crítica a los nodos regionales de Vertex AI para capitalizar la reducción del 40% en latencia y asegurar la continuidad operativa bajo legislación local.
- Rediseñar la arquitectura de agentes autónomos financieros y de retail explotando el procesamiento semántico nativo, eliminando las ineficiencias de traducción intermedia para lograr interacciones fluidas y culturalmente relevantes.
- Implementar protocolos de gobernanza de datos que aprovechen la soberanía de la infraestructura regional, garantizando que los prompts y la información corporativa sensible nunca crucen jurisdicciones extranjeras.
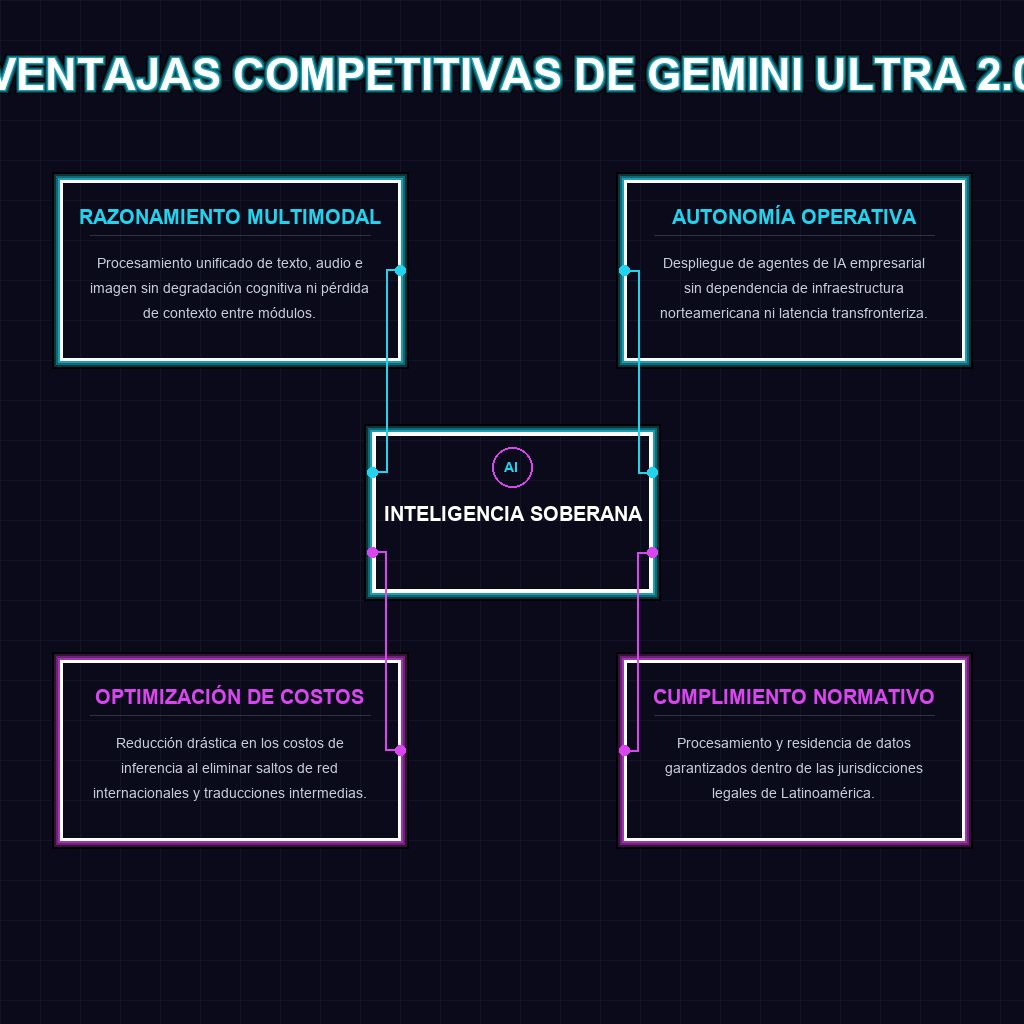
✦ VENTAJAS COMPETITIVAS DE GEMINI ULTRA 2.0
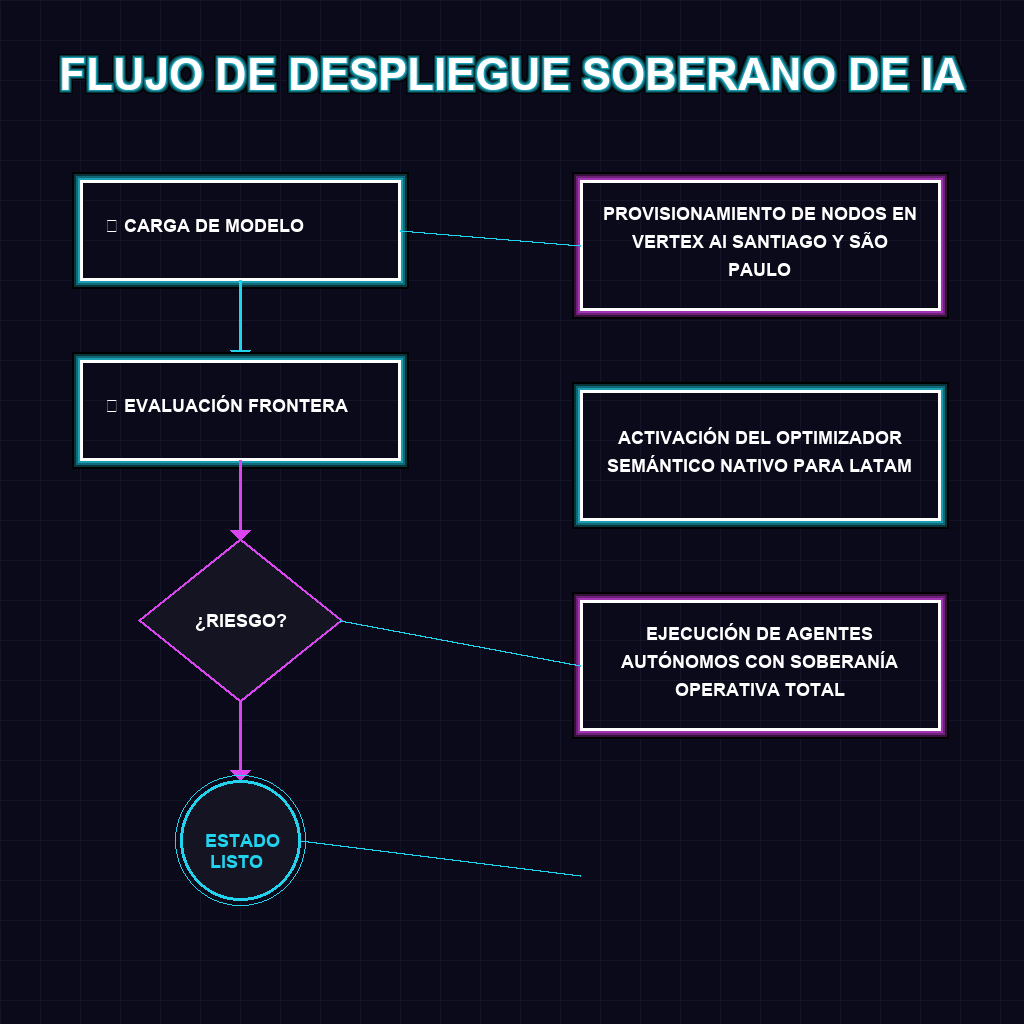
✦ FLUJO DE DESPLIEGUE SOBERANO DE IA
Preguntas Frecuentes
✦ ¿Qué significa exactamente el optimizador semántico nativo para español y portugués?
Significa que el modelo ha sido reentrenado y sus matrices de atención ajustadas para comprender la estructura gramatical, jergas y matices culturales del español y portugués directamente, sin pasar por una traducción interna al inglés. Esto elimina la pérdida de significado y acelera el tiempo de respuesta de inferencia.
✦ ¿Cómo afecta la reducción del 40% en latencia a los agentes autónomos empresariales?
Una latencia reducida permite que los agentes autónomos tomen decisiones en tiempo real crítico. En sectores como el financiero o retail, esto se traduce en la capacidad de procesar miles de transacciones, detectar fraudes o ajustar cadenas de suministro en milisegundos, una ventaja competitiva letal frente a sistemas basados en el extranjero.
✦ ¿Por qué es crucial la disponibilidad en las regiones de Vertex AI en Santiago y São Paulo?
Al procesar los datos localmente en Chile y Brasil, se garantiza la soberanía operativa. Los datos y prompts de las empresas nunca abandonan la jurisdicción latinoamericana, cumpliendo con las normativas locales de privacidad y evitando interrupciones por disputas legales o caídas de red en Norteamérica.
Fuente original de referencia: Google Cloud News
📥 Descarga el Recurso Gratuito
Prepara tus canales de venta, automatizaciones y aplicaciones móviles para el nuevo paradigma de agentes de voz impulsados por IA.

