
El futuro computacional de Latinoamérica acaba de encenderse. Amazon Web Services ha activado en São Paulo su primer clúster masivo de inferencia impulsado por chips Trainium3, rompiendo la dependencia histórica de la región hacia servidores en Norteamérica. Esta infraestructura nativa para IA generativa promete reducir un 60% los costos de inferencia frente a las GPUs tradicionales, integrándose de forma fluida con Amazon Bedrock y SageMaker. Las fintech y startups brasileñas ahora pueden escalar aplicaciones conversacionales con márgenes de rentabilidad sin precedentes.
✦ ARQUITECTURA DE INFERENCIA TRAINIUM3
Análisis del Acontecimiento y Contexto Tecnológico
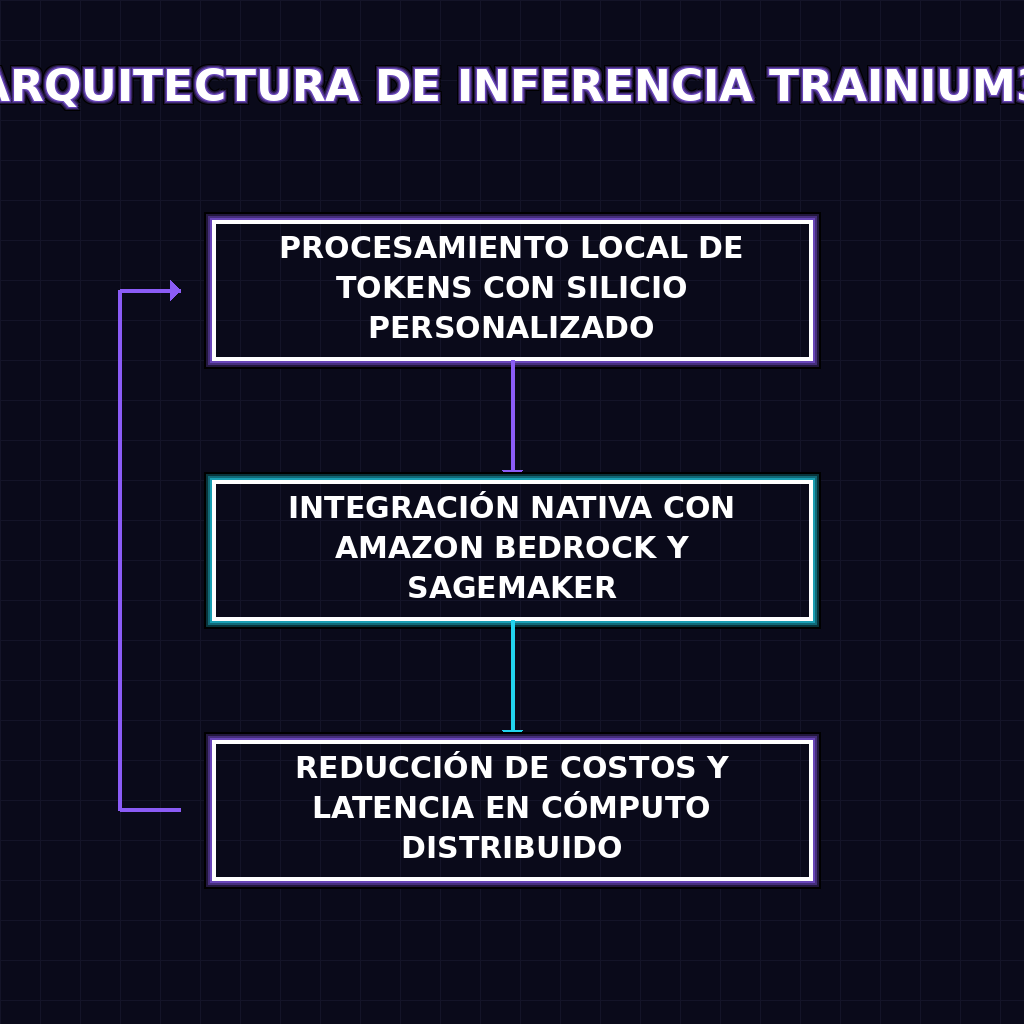
La activación del clúster Trainium3 en territorio brasileño representa un hito en la arquitectura de sistemas distribuidos para el hemisferio sur. Hasta ahora, la latencia inherente al enrutamiento de inferencia hacia regiones como Virginia o Ohio imponía un cuello de botella inaceptable para aplicaciones conversacionales en tiempo real. Al eliminar este salto interoceánico, los modelos de lenguaje grande desplegados a través de Amazon Bedrock operan con tiempos de respuesta optimizados, una métrica crítica para la experiencia de usuario en asistentes financieros y agentes de soporte. Además, el silicio personalizado de Trainium3 está diseñado específicamente para ejecutar cálculos matriciales de alta densidad con una eficiencia energética superior a la de las GPUs de propósito general, lo que permite a las empresas procesar miles de millones de tokens diarios sin que la infraestructura colapse bajo su propio peso térmico y financiero.
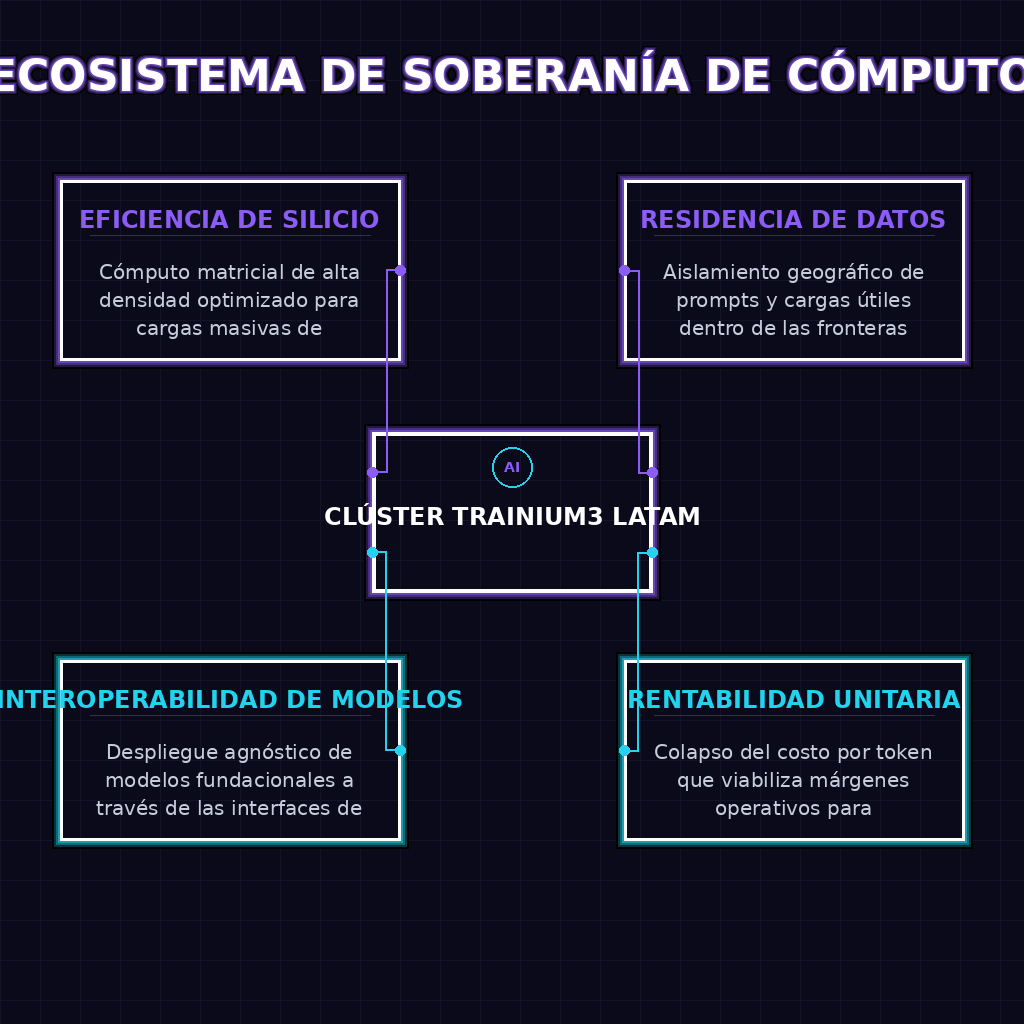
A largo plazo, esta movida de AWS reescribe las reglas del juego geopolítico y económico del cómputo en la nube en LATAM. La soberanía de datos y de procesamiento de IA deja de ser una aspiración teórica para convertirse en una realidad táctica. Las corporaciones latinoamericanas que antes debían lidiar con regulaciones de tránsito de datos internacionales ahora pueden mantener todo el ciclo de vida de la inferencia dentro de las fronteras regionales, garantizando cumplimiento normativo y protección de propiedad intelectual. Este ecosistema localizado catalizará una nueva generación de startups de IA nativa, capaces de competir globalmente gracias a márgenes de rentabilidad viables. La democratización del cómputo de inferencia a escala masiva obligará a los competidores a acelerar sus propios despliegues regionales, desatando una guerra de infraestructura que beneficiará directamente la capacidad de innovación de todo el ecosistema tecnológico latinoamericano.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el tejido empresarial latinoamericano, este clúster no es simplemente una mejora de velocidad; es la eliminación de la barrera de entrada para la IA de producción. Las fintech, healthtechs y startups conversacionales de la región han luchado históricamente con márgenes brutos devorados por los costos de inferencia en GPUs foráneas. Con Trainium3 en São Paulo, la ecuación unitaria por token se colapsa favorablemente, permitiendo escalar productos de IA generativa con rentabilidad desde el primer día, al mismo tiempo que se asegura la residencia de datos críticos dentro de la jurisdicción local.
- Optimización extrema de costos operativos: Reducir un 60% el gasto en inferencia transforma prototipos de IA no rentables en unidades de negocio escalables y autosuficientes.
- Soberanía computacional y latencia cero: Mantener el procesamiento de datos sensibles y prompts corporativos dentro de LATAM garantiza cumplimiento regulatorio y respuestas en tiempo real.
- Adopción acelerada de modelos de terceros: La integración nativa con Bedrock permite a las empresas intercambiar y escalar modelos fundacionales sin fricciones de infraestructura ni contratos bloqueantes.
✦ ECOSISTEMA DE SOBERANÍA DE CÓMPUTO
✦ FLUJO DE DESPLIEGUE Y ESCALABILIDAD
Preguntas Frecuentes
✦ ¿Qué diferencia al chip Trainium3 de las GPUs tradicionales para inferencia?
Trainium3 es un acelerador de silicio personalizado diseñado exclusivamente para las operaciones matriciales y cálculos intensivos que requiere la IA generativa. A diferencia de las GPUs de propósito general que desperdician recursos en lógica gráfica, Trainium3 optimiza cada transistor para procesamiento de tokens, resultando en una eficiencia energética y de costo superior, logrando una reducción de hasta un 60% en el gasto de inferencia.
✦ ¿Por qué es crucial la ubicación del clúster en São Paulo para LATAM?
Antes de este clúster, la inferencia para aplicaciones latinoamericanas se enrutaba a centros de datos en Norteamérica, sufriendo latencia de red y riesgos de cumplimiento normativo por transferencia internacional de datos. Al procesar localmente en São Paulo, se elimina la latencia interoceánica, se garantiza la soberanía y residencia de datos dentro de la región, y se habilita una experiencia de usuario en tiempo real para agentes conversacionales.
✦ ¿Cómo beneficia específicamente la integración nativa con Amazon Bedrock y SageMaker?
Esta integración permite a los desarrolladores acceder a modelos de IA de terceros sin tener que gestionar la infraestructura subyacente. Bedrock ofrece un catálogo de modelos fundacionales listos para usar mediante API, mientras que SageMaker permite el ajuste fino y entrenamiento personalizado. Al estar conectados nativamente al clúster Trainium3, ambas plataformas operan con máxima eficiencia y mínimo esfuerzo operativo.
Fuente original de referencia: AWS News Blog
📥 Descarga el Recurso Gratuito
Accede a nuestro catálogo de agentes de IA empresariales autónomos, diseñados con arquitecturas de runtime robustas.

