
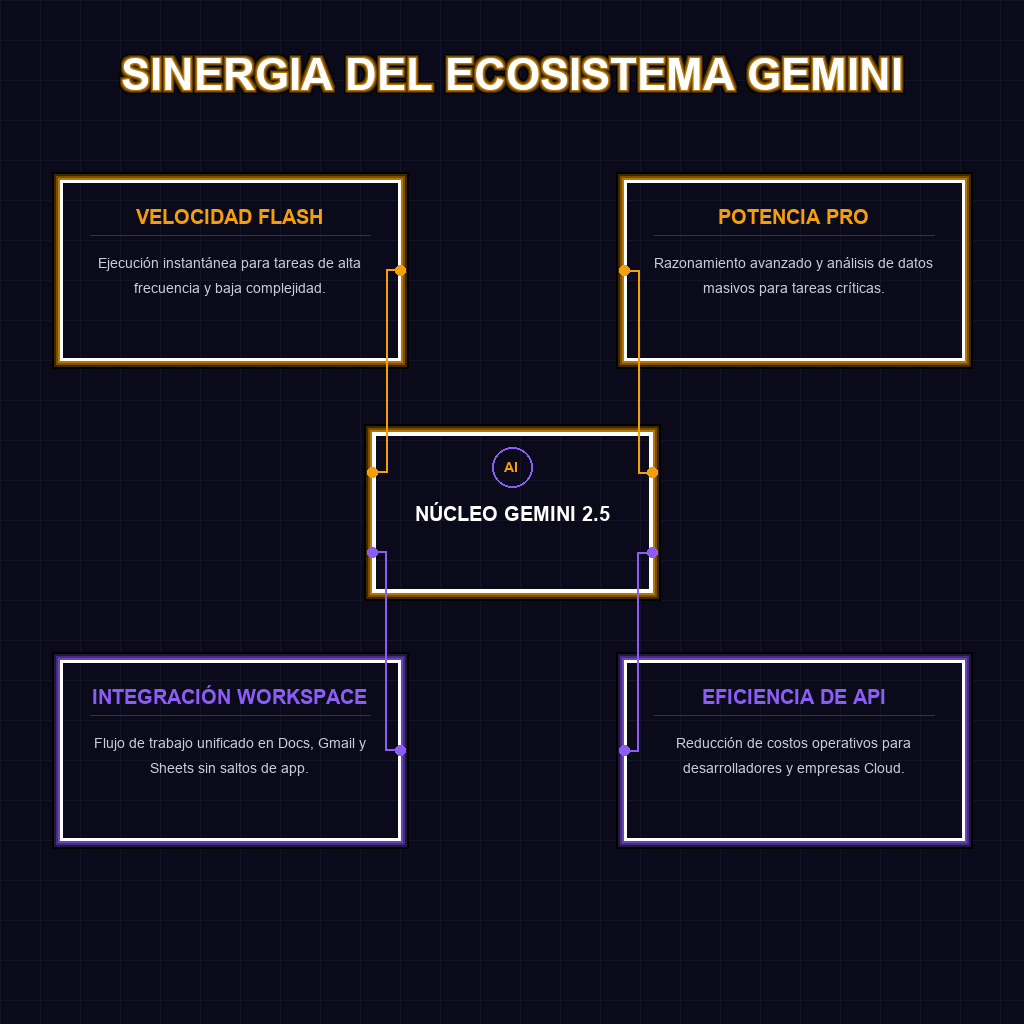
Google redefine la velocidad de la inteligencia artificial al desplegar Gemini 2.5 Flash como el motor neurálgico de todo su ecosistema. Esta transición no es un simple ajuste técnico, sino un movimiento estratégico para eliminar la fricción entre la intención del usuario y la respuesta de la máquina. Al priorizar la eficiencia y la baja latencia, Google transforma la IA de una herramienta de consulta a una capa de asistencia invisible, instantánea y omnipresente en la productividad global.
✦ ARQUITECTURA DE DESPLIEGUE FLASH
Análisis del Acontecimiento y Contexto Tecnológico
La implementación de Gemini 2.5 Flash marca el inicio de la era de los modelos destilados de alto rendimiento. Técnicamente, Flash está diseñado para maximizar el throughput sin sacrificar la ventana de contexto, permitiendo que tareas cotidianas de búsqueda y redacción se ejecuten en milisegundos. Al desplazar la carga de trabajo desde modelos masivos hacia arquitecturas optimizadas, Google resuelve el cuello de botella de la inferencia, logrando que la IA sea viable en tiempo real para millones de usuarios simultáneos sin colapsar la infraestructura de cómputo.
A largo plazo, este movimiento acelera la comoditización de la inteligencia artificial generativa. La batalla ya no se libra únicamente en la capacidad de razonamiento complejo, sino en la eficiencia operativa y el costo por token. Al reducir las barreras de entrada mediante la optimización de la API de Gemini 2.5 Pro, Google Cloud está forzando a sus competidores a optimizar sus modelos livianos para evitar la irrelevancia. Estamos transitando hacia un modelo híbrido donde la IA rápida gestiona el flujo y la IA profunda interviene solo en nodos de alta complejidad.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el tejido empresarial de Latinoamérica, esta actualización representa una ventana de oportunidad táctica. La reducción de latencias y la optimización de costos eliminan las principales barreras técnicas y financieras que impedían la escalabilidad de soluciones de IA en mercados emergentes.
- Democratización del acceso: La baja latencia permite implementar asistentes de IA efectivos incluso en regiones con conectividad inestable.
- Optimización de OPEX: Las nuevas tarifas de la API de Gemini 2.5 Pro permiten a las startups locales escalar sus productos sin comprometer su flujo de caja.
- Agilidad operativa: La integración nativa en Workspace permite a las PyMEs automatizar flujos de trabajo complejos sin necesidad de desarrollos costosos desde cero.
✦ SINERGIA DEL ECOSISTEMA GEMINI
✦ FLUJO DE ESCALABILIDAD EMPRESARIAL
Preguntas Frecuentes
✦ ¿Cuál es la diferencia real entre Gemini 2.5 Flash y Gemini 2.5 Pro?
Gemini 2.5 Flash está optimizado para la velocidad y la eficiencia, siendo ideal para tareas repetitivas, respuestas rápidas y despliegues masivos. Gemini 2.5 Pro es un modelo de razonamiento profundo, diseñado para análisis complejos, codificación avanzada y tareas que requieren una comprensión exhaustiva de contextos masivos.
✦ ¿Cómo impacta la optimización de la API de Google Cloud a los desarrolladores?
La optimización de costos reduce el gasto operativo por cada millón de tokens procesados. Esto permite que las empresas implementen agentes de IA más ambiciosos y procesen volúmenes de datos mucho mayores sin que el costo de la inferencia erosione los márgenes de beneficio del producto.
✦ ¿Notaré un cambio inmediato en el uso de Google Docs o Gmail?
Sí. La integración de Flash como modelo base reduce el tiempo de espera entre el prompt y la generación del texto. La experiencia se vuelve más fluida, eliminando las pausas prolongadas y permitiendo una interacción más natural y dinámica con las herramientas de productividad.
Fuente original de referencia: Google Keyword
📥 Descarga el Recurso Gratuito
Prepara tus canales de venta, automatizaciones y aplicaciones móviles para el nuevo paradigma de agentes de voz impulsados por IA.

