
Google Research enciende los motores del olvido cibernético. Su nuevo marco para auditar el desaprendizaje automático redefine la arquitectura de privacidad en la IA. En la era del cumplimiento normativo, borrar datos ya no es suficiente; la red neuronal debe demostrar verificablemente que ha purgado la información. Este hito técnico transforma el derecho al olvido en una métrica de ingeniería, blindando a las corporaciones contra sanciones y forjando el futuro de la IA ética.
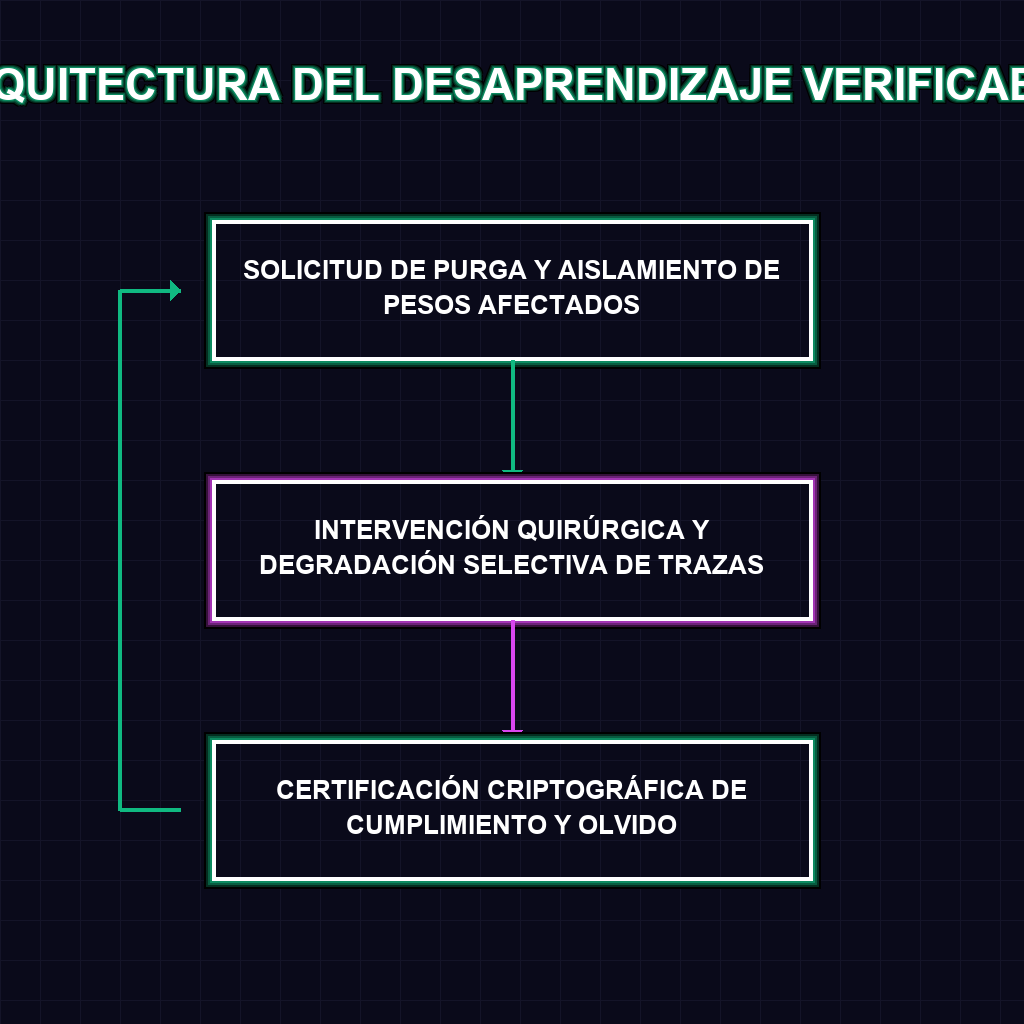
✦ ARQUITECTURA DEL DESAPRENDIZAJE VERIFICABLE
Análisis del Acontecimiento y Contexto Tecnológico
El tejido neuronal de los grandes modelos de lenguaje ha operado históricamente como una caja negra impenetrable, donde la entropía de los datos de entrenamiento se fundía en pesos y sesgos inextricables. La introducción de un marco de auditoría para el desaprendizaje automático por parte de Google Research es una ruptura radical con este paradigma. Tradicionalmente, la eliminación de datos sensibles requería una costosa reentrenamiento desde cero, un proceso energéticamente insostenible y temporalmente inviable para ecosistemas de IA a escala de producción. Este nuevo marco introduce mecanismos de verificación criptográfica y métricas de degradación selectiva, permitiendo a los ingenieros realizar una lobotomía quirúrgica en la red, extirpando trazas de datos específicos sin colapsar la topología general del conocimiento. La capacidad de certificar que una red neuronal ha olvidado una entidad o un conjunto de patrones no es solo un avance de ingeniería de software; es la fundación de una nueva arquitectura de confianza algorítmica.
A largo plazo, la estandarización del desaprendizaje verificable reconfigurará las dinámicas de poder entre la innovación tecnológica y la regulación cívica. Las corporaciones ya no podrán escudarse en la complejidad técnica para evadir el derecho al olvido, lo que forzará una migración masiva hacia arquitecturas de IA modulares y descentralizadas. Veremos el surgimiento de contratos inteligentes de destrucción de datos, donde la eliminación de información de un usuario se ejecutará y auditará en tiempo real a través de cadenas de bloques inmutables. Además, este marco catalizará la obsolescencia de los modelos monolíticos, impulsando el diseño de sistemas federados donde la memoria se pueda segregar y purgar de forma independiente por jurisdicción. Las empresas que no integren esta capacidad de olvido selectivo enfrentarán no solo multas asfixiantes bajo marcos como el RGPD o la Ley de IA, sino una erosión total de su capital reputacional en una economía donde la privacidad cuantificable será la moneda de cambio más valiosa.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el ecosistema corporativo de América Latina, este marco de auditoría no es una mera novedad técnica, sino un escudo táctico ante la inminente ola regulatoria global. Las startups y corporaciones de la región que procesan datos de usuarios europeos o norteamericanos deben adaptar sus pipelines de IA para integrar el desaprendizaje como un servicio nativo. La ventaja competitiva en LATAM residirá en ofrecer plataformas de IA que no solo sean precisas, sino jurídicamente ágiles, garantizando la purga de datos sin latencia operativa y evitando así el bloqueo de sus modelos en mercados extranjeros hiperregulados.
- Implementar pipelines de ingeniería de datos que integren el desaprendizaje automático como un endpoint obligatorio de API, no como una corrección posterior.
- Desarrollar capas de auditoría interna automatizadas para certificar la eliminación de datos de usuarios LATAM antes de cruzar fronteras regulatorias internacionales.
- Capitalizar el marco de Google para posicionar soluciones de IA regionales como ‘compliance-ready’ por defecto, atrayendo inversión extranjera preocupada por la privacidad.
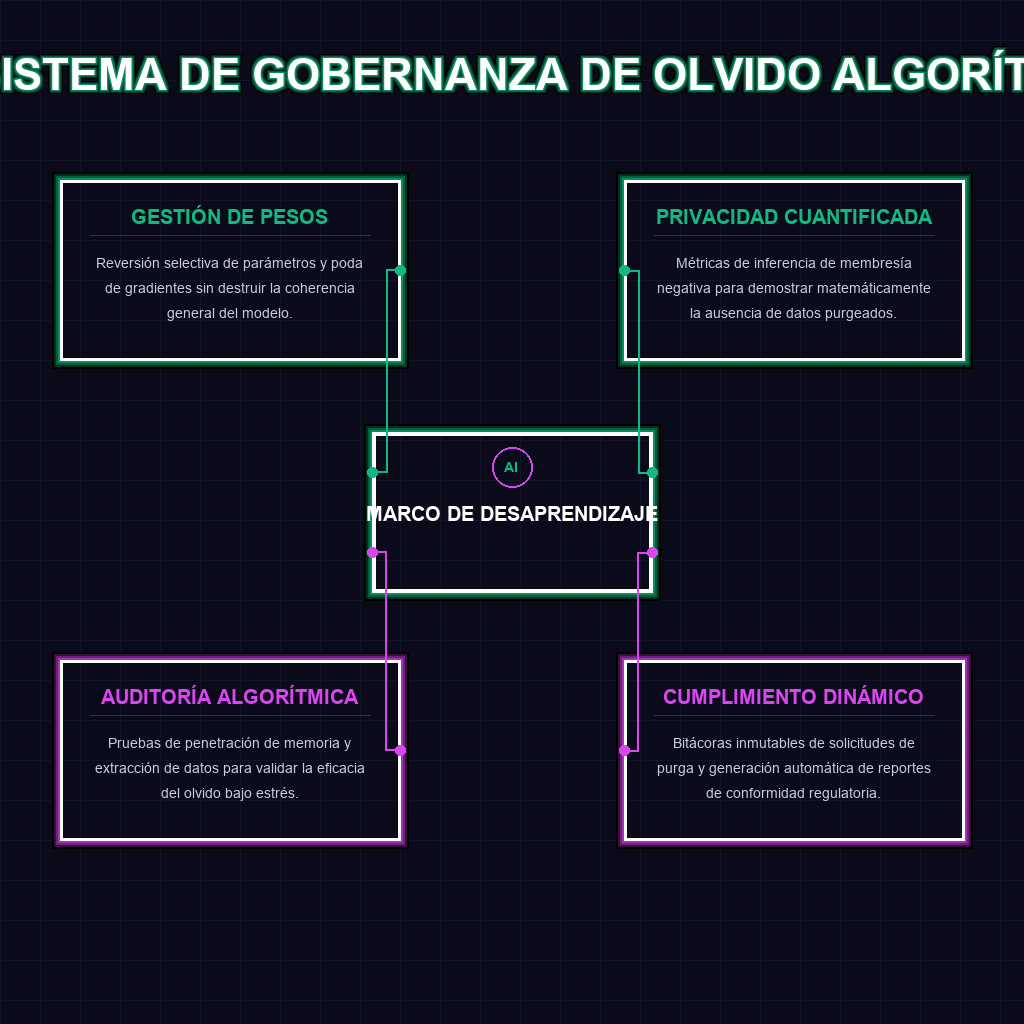
✦ ECOSISTEMA DE GOBERNANZA DE OLVIDO ALGORÍTMICO
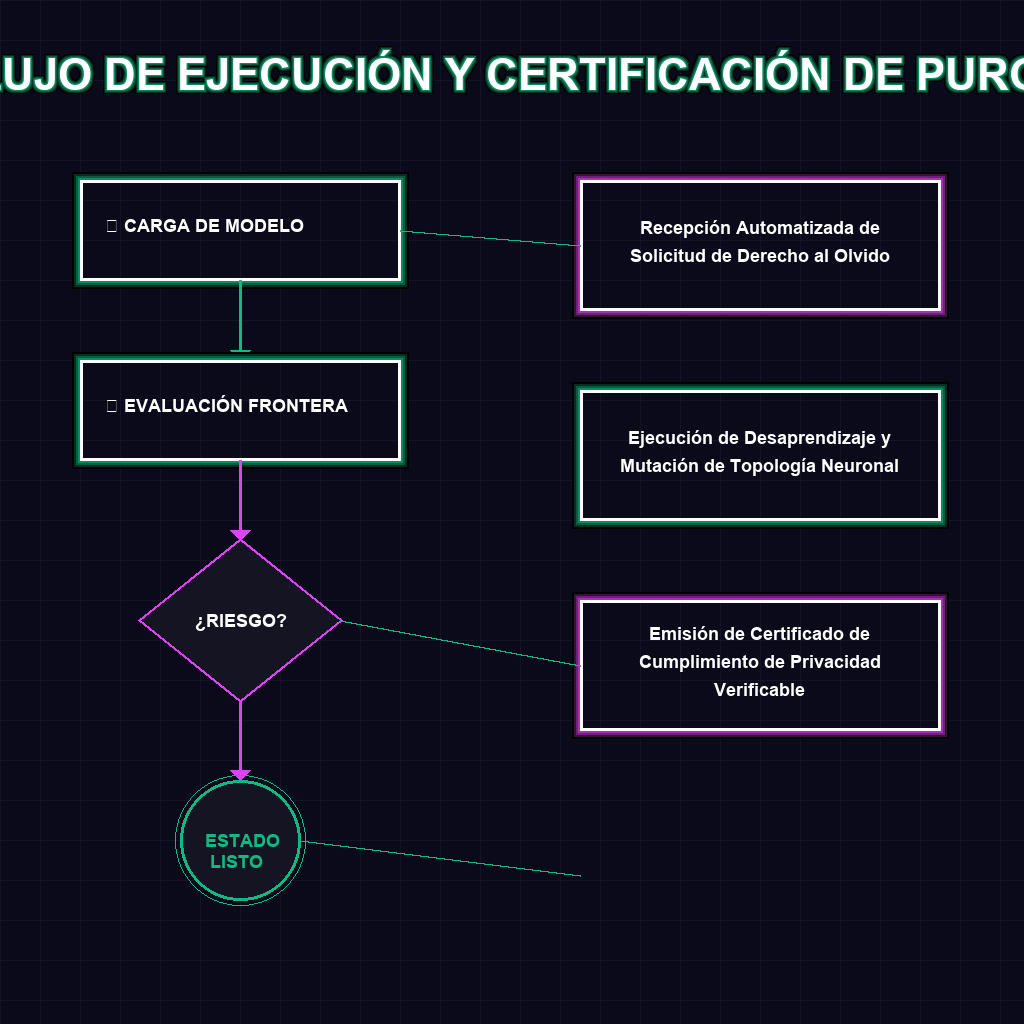
✦ FLUJO DE EJECUCIÓN Y CERTIFICACIÓN DE PURGA
Preguntas Frecuentes
✦ ¿Qué es exactamente el desaprendizaje automático o machine unlearning?
El desaprendizaje automático es un conjunto de técnicas de ingeniería de machine learning que permiten alterar un modelo de IA entrenado para que elimine de forma verificable la influencia de un subconjunto específico de datos de entrenamiento. En lugar de reentrenar el modelo desde cero, lo cual es prohibitivo en costos computacionales, se aplican algoritmos de inversión de gradientes y poda de pesos para ‘olvidar’ la información objetivo, manteniendo la utilidad general del sistema.
✦ ¿Por qué es crucial un marco de auditoría para el derecho al olvido en IA?
Porque la simple promesa de borrar datos ya no es legal ni técnicamente suficiente. En redes neuronales complejas, los datos persisten en formas distribuidas y latentes. Un marco de auditoría proporciona las herramientas matemáticas y de software para certificar y demostrar ante reguladores que la huella algorítmica de esos datos ha sido erradicada, cerrando la brecha entre el cumplimiento legal teórico y la ejecución técnica real.
✦ ¿Cómo impacta esto a las empresas que desarrollan o implementan IA?
Transforma la privacidad de un gasto pasivo en una métrica de ingeniería activa. Las empresas deben evolucionar sus arquitecturas para incluir capacidades nativas de desaprendizaje y auditoría. Aquellas que lo hagan reducirán drásticamente sus riesgos de sanciones regulatorias severas y ganarán una ventaja competitiva masiva al poder garantizar a sus usuarios y socios comerciales un estándar de privacidad verificable y de grado industrial.
Fuente original de referencia: Google Research Blog
📥 Descarga el Recurso Gratuito
Únete a la comunidad líder ‘IA Sin Filtro’ para aprender sobre inyección de prompts, seguridad y gobernanza de IA.

