El ecosistema de la inteligencia artificial enfrenta una disrupción legal inminente. La News/Media Alliance ha presionado al Congreso de EE.UU. para erradicar el scraping masivo y no remunerado de contenido editorial. Esta ofensiva busca imponer licencias obligatorias para los datos de entrenamiento, amenazando con reconfigurar la legalidad de la red y disparar los costos operativos de los grandes modelos de lenguaje. El paradigma del dato gratuito ha terminado.
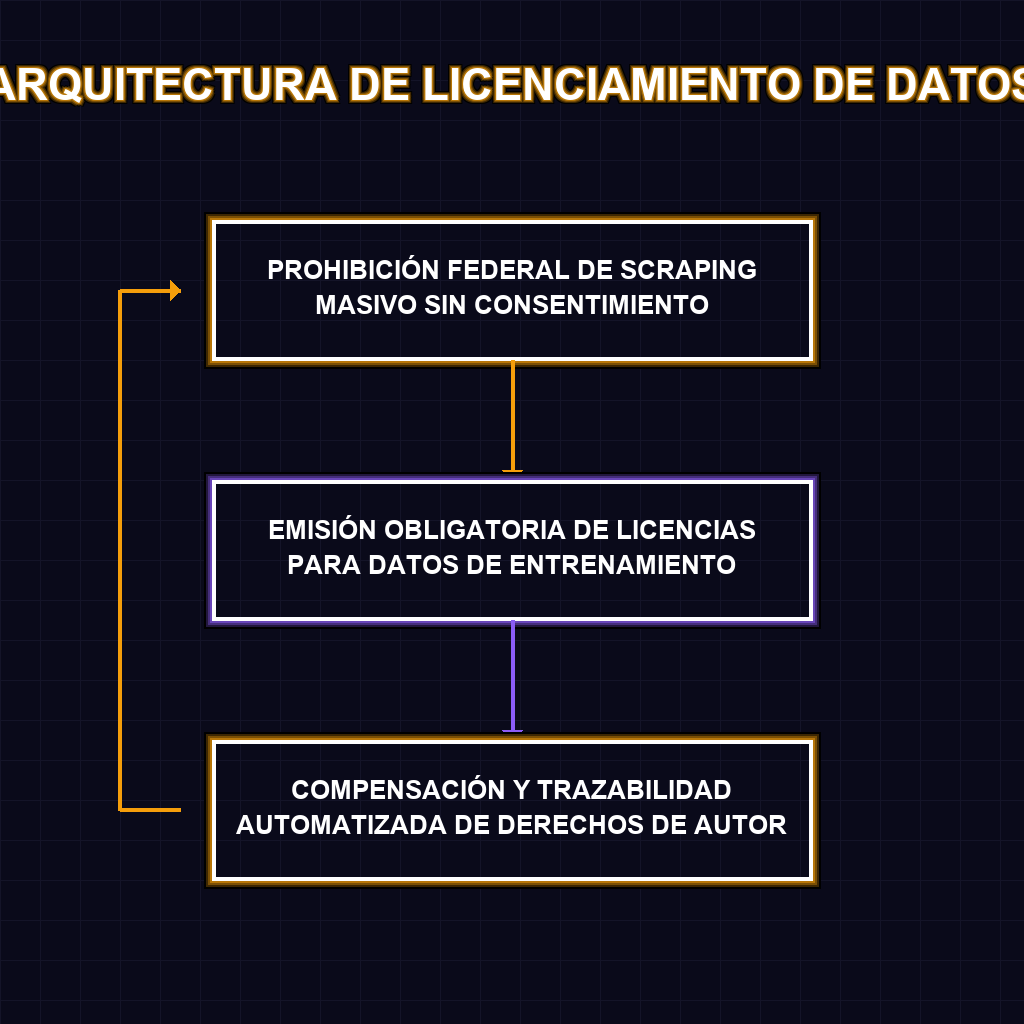
✦ ARQUITECTURA DE LICENCIAMIENTO DE DATOS
Análisis del Acontecimiento y Contexto Tecnológico
La extracción no autorizada de datos, conocida técnicamente como web scraping, ha sido el combustible barato que alimentó la explosión de los grandes modelos de lenguaje. La arquitectura de estos sistemas requiere ingerir terabytes de información para calibrar sus pesos neuronales, y el periodismo de alta calidad siempre ha sido un objetivo primordial por su estructura semántica y precisión factual. Sin embargo, la News/Media Alliance expone la falla sistémica en el núcleo de esta dinámica: las corporaciones de IA están empaquetando y devaluando la propiedad intelectual, externalizando los costos de producción editorial mientras monetizan la inferencia. La propuesta de una licencia obligatoria de datos de entrenamiento no es solo una barrera legal; es un mecanismo de mercado para restaurar la viabilidad económica del ecosistema mediático. Si el contenido es el nodo de valor, la extracción sin compensación es un fallo de diseño en la economía de la IA que el Congreso ahora debe parchear.
Las repercusiones de esta regulación trascienden el ámbito mediático y golpean directamente la viabilidad financiera de los desarrolladores de modelos fundacionales. La imposición de licencias obligatorias destruye el mito del datos públicos gratuitos, disparando exponencialmente los costos de adquisición de datasets y alargando los ciclos de entrenamiento por auditorías de derechos de autor. A largo plazo, asistiremos a la consolidación de un oligopolio donde solo las corporaciones con capital masivo podrán costear corpus legales, sofocando la innovación en modelos open-source. Además, esto catalizará el surgimiento de un mercado secundario de datos sintéticos y licenciamiento corporativo B2B, forzando a la industria a migrar hacia arquitecturas de IA más eficientes en términos de datos o a depender de federaciones de contenido cerrado. La legalidad del entrenamiento con datos públicos de internet se fractura, estableciendo un nuevo paradigma donde el derecho a rastrear será un activo tokenizable y altamente disputado.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el ecosistema tech en América Latina, este choque regulatorio no es una amenaza distante, sino una oportunidad táctica inmediata. Las startups y desarrolladores latinoamericanos deben percibir el encarecimiento del scraping en EE.UU. como una ventana para construir infraestructura de datos propia, ética y compliant. Las empresas de medios regionales tienen la posibilidad de federar sus archivos históricos y negociar licencias de entrenamiento en bloque, generando una nueva línea de ingresos en divisas. La escasez de datos legales globales posiciona a LATAM como un reservorio de contenido en español altamente estructurado, listo para ser tokenizado y comercializado bajo marcos de gobernanza propios.
- Desarrollar pipelines de datos limpios y licenciados en español para abastecer la futura demanda global de LLMs compliant.
- Federar archivos mediáticos regionales para negociar derechos de entrenamiento con desarrolladores de IA, monetizando activos intelectuales subutilizados.
- Implementar arquitecturas de IA basadas en modelos más pequeños y eficientes (SLMs) que requieran menos datos, evadiendo la dependencia de scraping masivo.
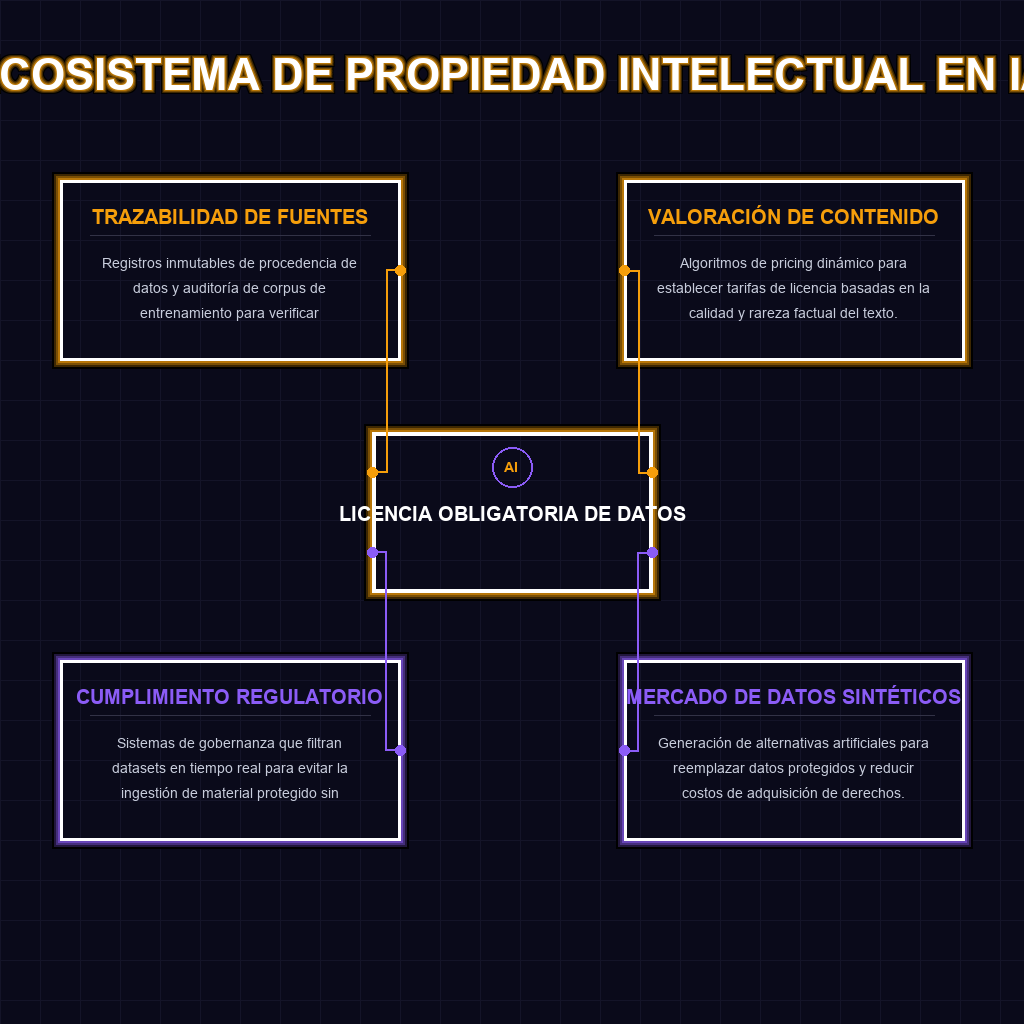
✦ ECOSISTEMA DE PROPIEDAD INTELECTUAL EN IA
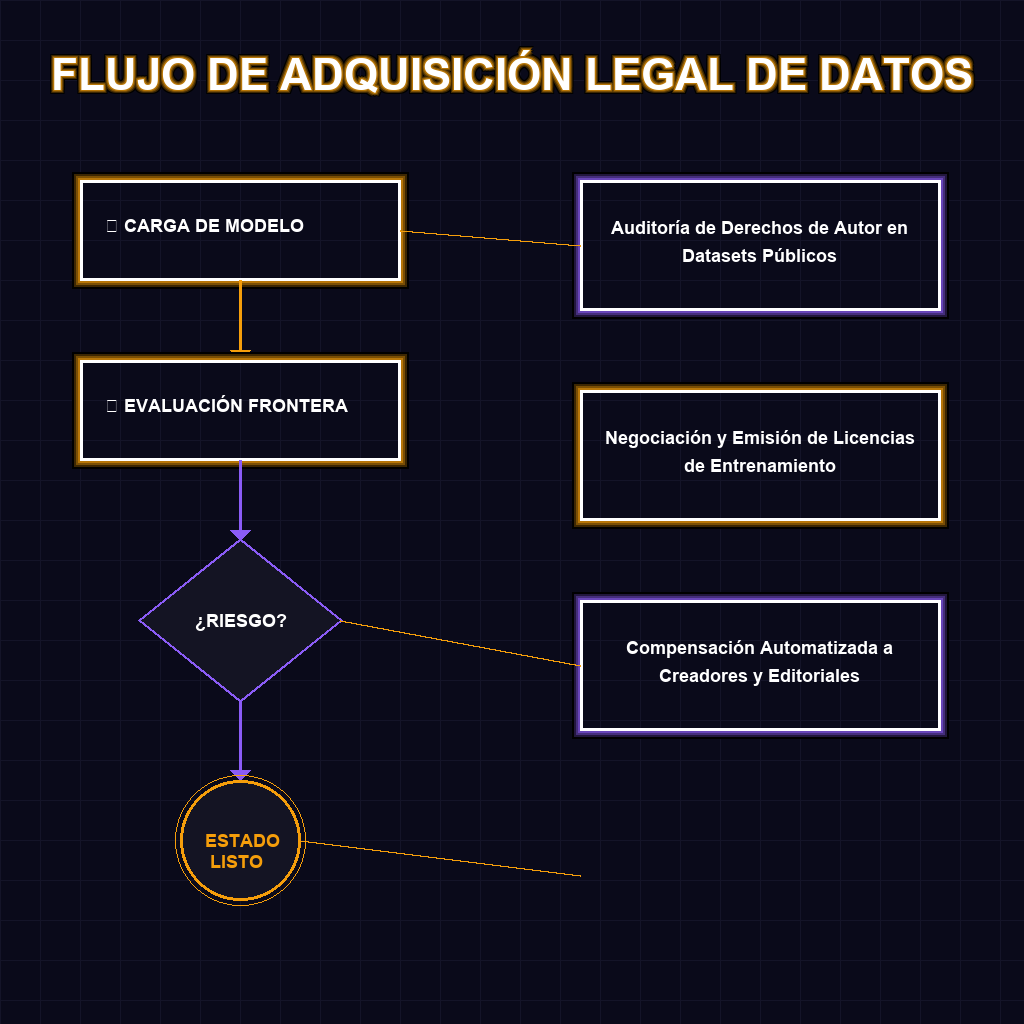
✦ FLUJO DE ADQUISICIÓN LEGAL DE DATOS
Preguntas Frecuentes
✦ ¿Qué es exactamente el scraping masivo y por qué es controversial para la IA?
El scraping masivo es la extracción automatizada de grandes volúmenes de datos de sitios web mediante bots. En el contexto de IA, es controversial porque los desarrolladores de modelos de lenguaje utilizan esta técnica para recolectar texto de noticias y artículos sin pagar por los derechos de autor, aprovechando el trabajo editorial para entrenar sistemas comerciales que luego compiten directamente con los medios originales.
✦ ¿Cómo afectará la licencia obligatoria de datos a los modelos de código abierto?
La licencia obligatoria incrementará drásticamente los costos de desarrollo, ya que los creadores de modelos deberán presupuestar el pago de derechos. Esto podría marginar a los proyectos de código abierto que dependen de datos públicos gratuitos, forzándolos a depender de datasets más pequeños, de menor calidad o de datos sintéticos, a menos que se establezcan excepciones regulatorias para la investigación y el desarrollo no comercial.
✦ ¿Puede la inteligencia artificial funcionar sin hacer scraping de contenido protegido?
Sí, pero requiere un cambio de paradigma. Las alternativas incluyen el entrenamiento exclusivo con datos de dominio público, la generación de datos sintéticos mediante modelos más pequeños, y el uso de arquitecturas de modelos más eficientes que requieren menos datos para alcanzar el mismo rendimiento. Sin embargo, la calidad factual y la reducción de alucinaciones se verán comprometidas sin acceso a contenido editorial de alta calidad.
Fuente original de referencia: Capitol Pressroom
📥 Descarga el Recurso Gratuito
Prepara tus canales de venta, automatizaciones y aplicaciones móviles para el nuevo paradigma de agentes de voz impulsados por IA.

