
La frontera de la inteligencia artificial se desplaza hacia la eficiencia extrema. El nuevo paper BitsMoE redefine la cuantificación de modelos Mixture-of-Experts (MoE), implementando una asignación de bits guiada por energía espectral. Esta innovación permite comprimir LLMs masivos sin sacrificar la capacidad cognitiva, rompiendo la barrera entre la potencia de cómputo industrial y la viabilidad operativa en entornos restringidos. Estamos ante el fin de la era del gasto energético indiscriminado para dar paso a la IA pragmática y sostenible.
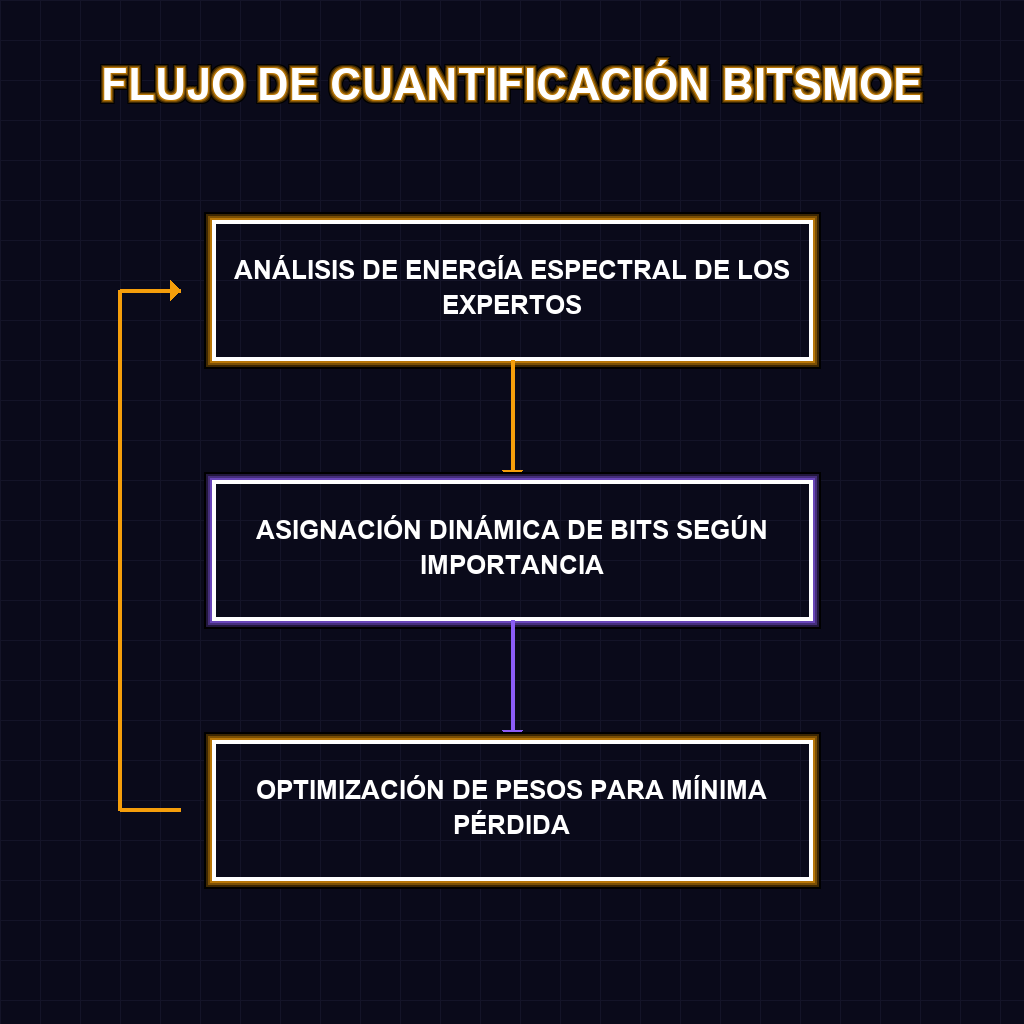
✦ FLUJO DE CUANTIFICACIÓN BITSMOE
Análisis del Acontecimiento y Contexto Tecnológico
Técnicamente, los modelos MoE son arquitecturas híbridas que activan solo una fracción de sus parámetros por token, lo que los hace increíblemente potentes pero difíciles de cuantificar debido a la heterogeneidad de sus expertos. BitsMoE introduce un enfoque disruptivo: el análisis de energía espectral. En lugar de aplicar una cuantificación uniforme que degrada el rendimiento, este método identifica qué componentes del modelo retienen la mayor cantidad de información crítica. Al asignar más bits a las dimensiones de alta energía y reducir los bits en las redundantes, se logra una compresión inteligente que mantiene la perplejidad del modelo mientras reduce drásticamente la huella de memoria VRAM.
A largo plazo, la implementación de BitsMoE cataliza la transición hacia el Edge AI de alta gama. La capacidad de ejecutar modelos MoE cuantificados eficientemente significa que la inteligencia de frontera ya no residirá exclusivamente en clusters de GPUs masivos, sino que podrá migrar a servidores locales y dispositivos finales. Esto no solo reduce la latencia y los costos de inferencia, sino que redefine la soberanía de datos. La industria se moverá hacia un ecosistema donde la eficiencia espectral sea el estándar, permitiendo que modelos con billones de parámetros operen con una fracción del consumo energético actual, haciendo la IA escalable y financieramente viable.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el ecosistema empresarial en Latinoamérica, donde el acceso a hardware de última generación es costoso y la infraestructura de nube puede ser inestable, BitsMoE representa una ventana de oportunidad competitiva. La capacidad de desplegar modelos MoE optimizados permite a las empresas locales ejecutar IA de vanguardia con presupuestos de infraestructura reducidos.
- Reducción de OpEx: Menor dependencia de instancias de GPU costosas en la nube mediante la optimización de VRAM.
- Soberanía Tecnológica: Posibilidad de desplegar modelos frontera en servidores on-premise locales sin pérdida de rendimiento.
- Democratización del Acceso: Implementación de soluciones de IA avanzada en sectores con hardware limitado, acelerando la transformación digital regional.
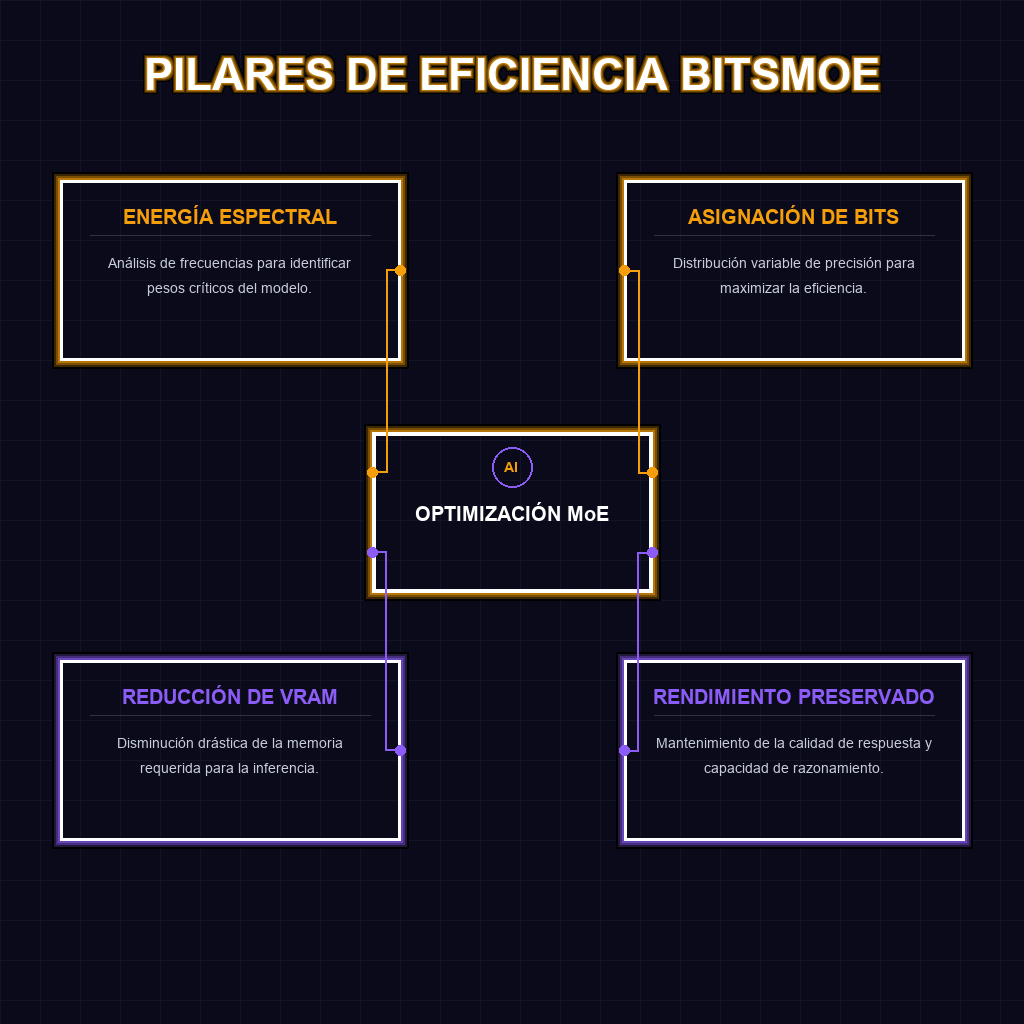
✦ PILARES DE EFICIENCIA BITSMOE
✦ IMPACTO EN EL DESPLIEGUE DE IA
Preguntas Frecuentes
✦ ¿Qué es exactamente la arquitectura Mixture-of-Experts (MoE)?
Es un diseño de red neuronal donde el modelo contiene múltiples sub-redes especializadas llamadas expertos. En lugar de usar todos los parámetros para cada entrada, un mecanismo de enrutamiento selecciona solo los expertos más aptos, optimizando el cómputo sin reducir la capacidad total del modelo.
✦ ¿En qué se diferencia la cuantificación de BitsMoE de la tradicional?
La cuantificación tradicional suele reducir la precisión de todos los pesos por igual (ej. de 16 bits a 4 bits). BitsMoE es selectivo: utiliza la energía espectral para decidir dónde mantener alta precisión y dónde reducirla, evitando que la pérdida de bits afecte las partes vitales del razonamiento del modelo.
✦ ¿Cómo beneficia esto a una empresa que no desarrolla modelos, sino que los consume?
Beneficia directamente la rentabilidad. Al requerir menos memoria y cómputo, el costo de hosting de los modelos disminuye y la velocidad de respuesta (tokens por segundo) aumenta, permitiendo ofrecer productos de IA más rápidos y económicos al cliente final.
Fuente original de referencia: arXiv
📥 Descarga el Recurso Gratuito
Accede a nuestro catálogo de agentes de IA empresariales autónomos, diseñados con arquitecturas de runtime robustas.

