
La frontera del razonamiento artificial se ha desplazado. NVIDIA Nemotron 3 Ultra llega a Amazon SageMaker JumpStart, desplegando una bestia de 550 mil millones de parámetros diseñada para aniquilar la latencia y optimizar el costo. No estamos ante un simple modelo de lenguaje, sino ante el motor definitivo para la nueva generación de agentes autónomos que operan en tiempo real y a escala industrial, redefiniendo la eficiencia operativa en la nube.
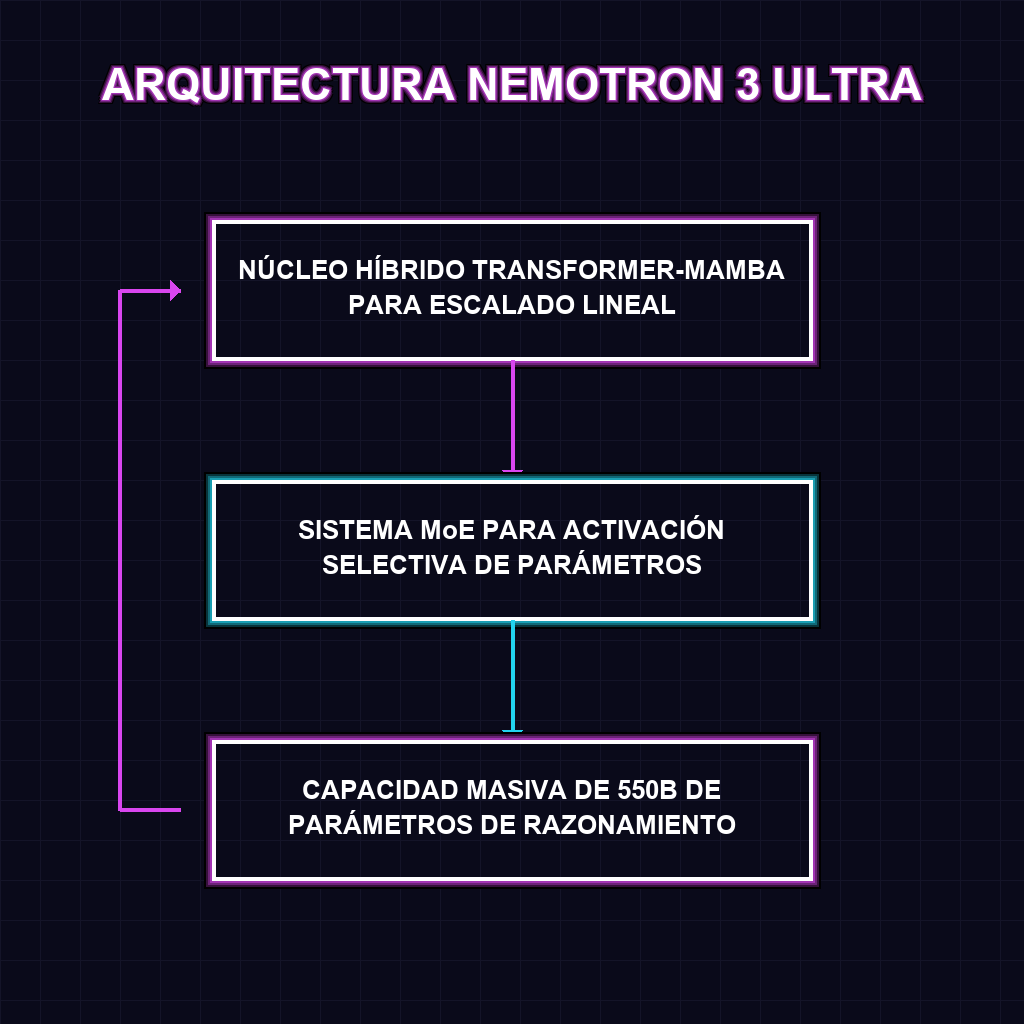
✦ ARQUITECTURA NEMOTRON 3 ULTRA
Análisis del Acontecimiento y Contexto Tecnológico
El núcleo técnico de Nemotron 3 Ultra reside en su arquitectura híbrida Transformer-Mamba Mixture-of-Experts (MoE). Mientras que los Transformers tradicionales luchan con la complejidad cuadrática del contexto, la integración de Mamba permite una gestión de secuencias mucho más eficiente y lineal. Al combinar esto con un sistema MoE, el modelo no activa la totalidad de sus 550B de parámetros para cada token, sino que enruta la información hacia los expertos más aptos, logrando una inferencia 5 veces más veloz sin sacrificar la profundidad del razonamiento lógico.
A largo plazo, este despliegue marca el fin de la era de los chatbots reactivos y el inicio de la era de los agentes de IA de larga duración. La reducción del 30% en el costo por token elimina la barrera económica para implementar flujos de trabajo complejos donde la IA debe razonar, iterar y ejecutar tareas autónomas durante periodos prolongados. Estamos presenciando la democratización del cómputo de frontera, permitiendo que la inteligencia de nivel Ultra se convierta en una utilidad básica para cualquier infraestructura empresarial moderna que busque automatizar procesos cognitivos complejos.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el ecosistema empresarial en Latinoamérica, la disponibilidad de Nemotron 3 Ultra en la nube de AWS representa un salto cuántico en competitividad tecnológica. La capacidad de despliegue ‘day-zero’ permite que startups y corporaciones regionales accedan a modelos de razonamiento masivo sin la necesidad de invertir en infraestructura de hardware prohibitiva, nivelando el campo de juego frente a los gigantes globales.
- Optimización de OPEX: La reducción de costos por token permite escalar servicios de IA generativa sin que el gasto operativo devore los márgenes de beneficio locales.
- Agilidad de Mercado: El despliegue inmediato vía SageMaker reduce el tiempo de lanzamiento de productos basados en agentes autónomos de meses a solo días.
- Soberanía de Implementación: Capacidad de ejecutar razonamiento de frontera sobre flujos de datos regionales utilizando la infraestructura robusta y segura de AWS.
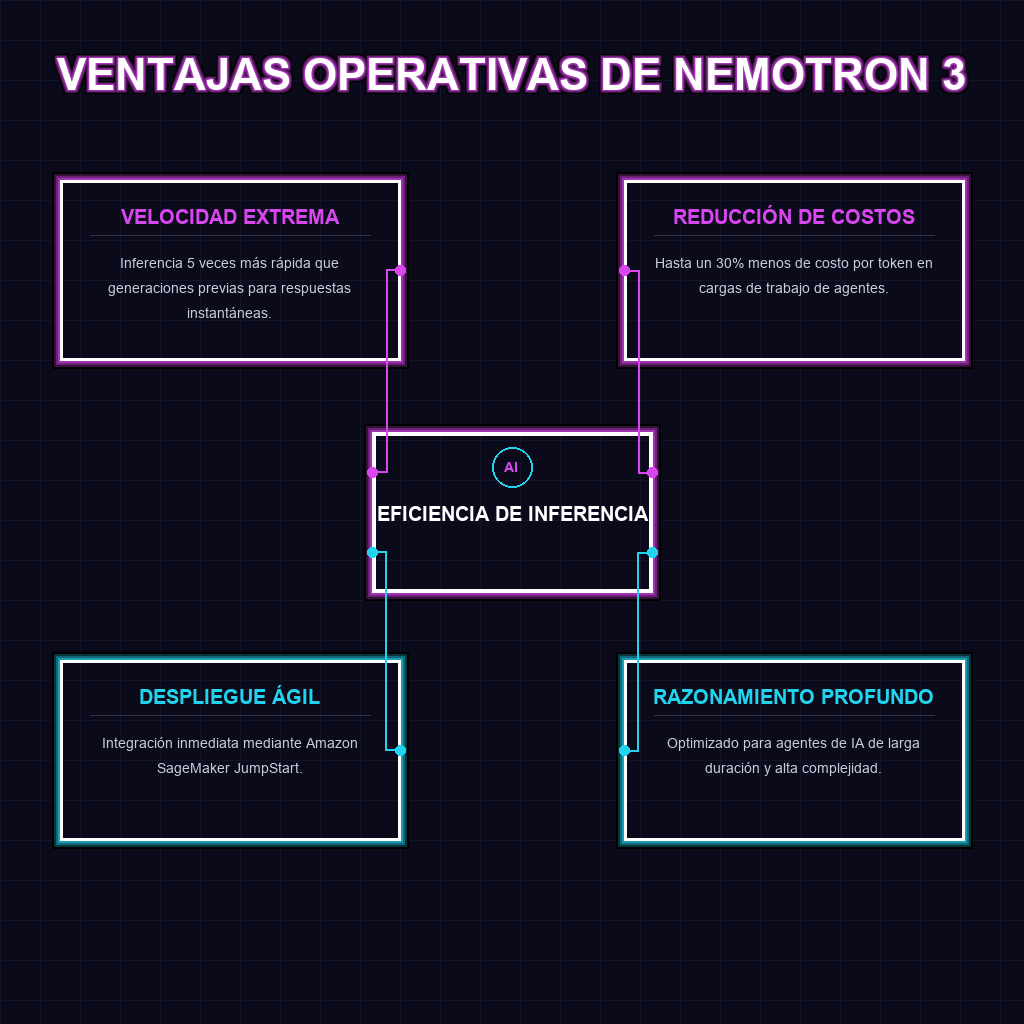
✦ VENTAJAS OPERATIVAS DE NEMOTRON 3
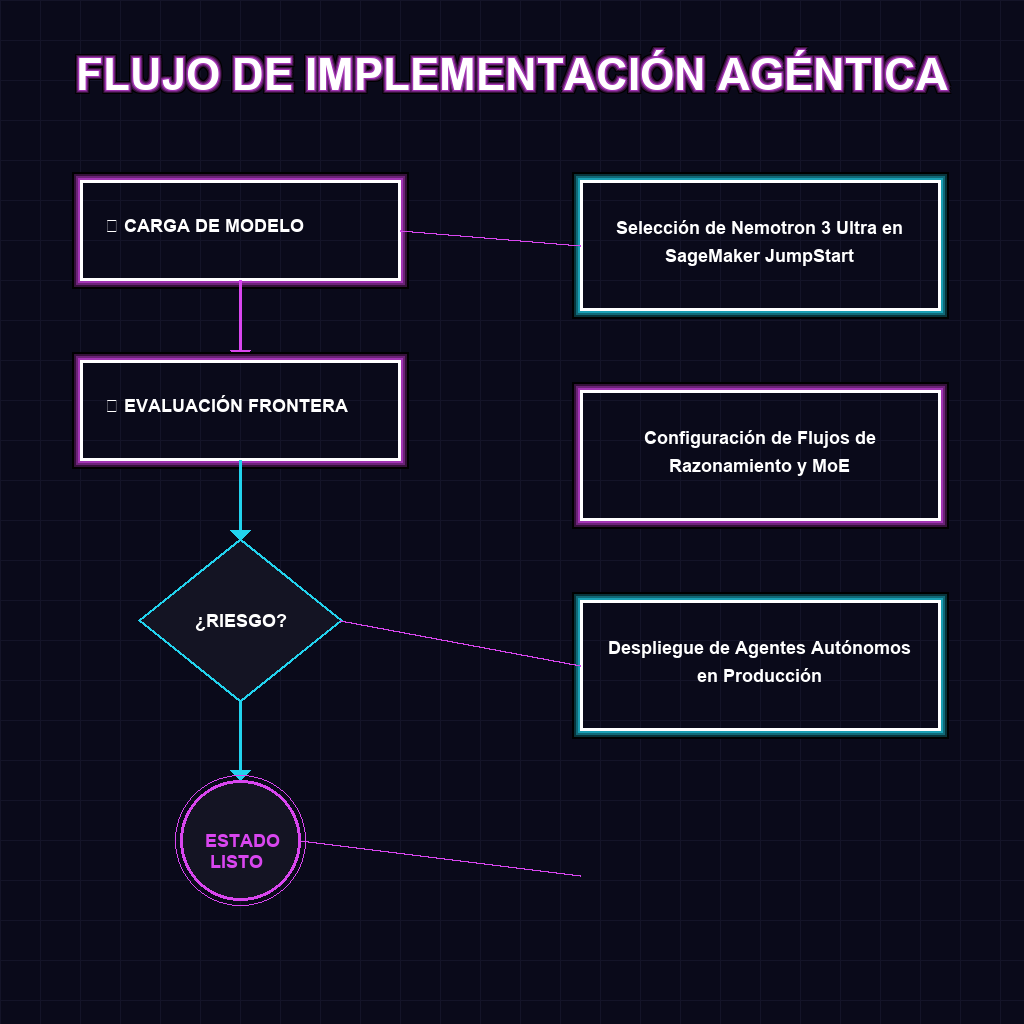
✦ FLUJO DE IMPLEMENTACIÓN AGÉNTICA
Preguntas Frecuentes
✦ ¿Qué es la arquitectura Transformer-Mamba?
Es una fusión innovadora que combina la capacidad de atención global de los Transformers con la eficiencia de procesamiento lineal de los modelos Mamba, permitiendo manejar contextos masivos con una fracción del cómputo tradicional.
✦ ¿Cómo impacta el Mixture-of-Experts (MoE) en el rendimiento?
El MoE permite que el modelo sea masivo en conocimiento pero eficiente en ejecución, ya que solo activa las sub-redes o ‘expertos’ necesarios para cada tarea específica, disparando la velocidad de inferencia y reduciendo el consumo de energía.
✦ ¿Por qué este modelo es crítico para los agentes de IA?
Los agentes autónomos requieren múltiples ciclos de razonamiento interno antes de ejecutar una acción. Al ser 5 veces más rápido y significativamente más barato, Nemotron 3 Ultra hace que estos ciclos de pensamiento sean viables económicamente en entornos de producción real.
Fuente original de referencia: Unrot.co
📥 Descarga el Recurso Gratuito
Únete a la comunidad líder ‘IA Sin Filtro’ para aprender sobre inyección de prompts, seguridad y gobernanza de IA.

