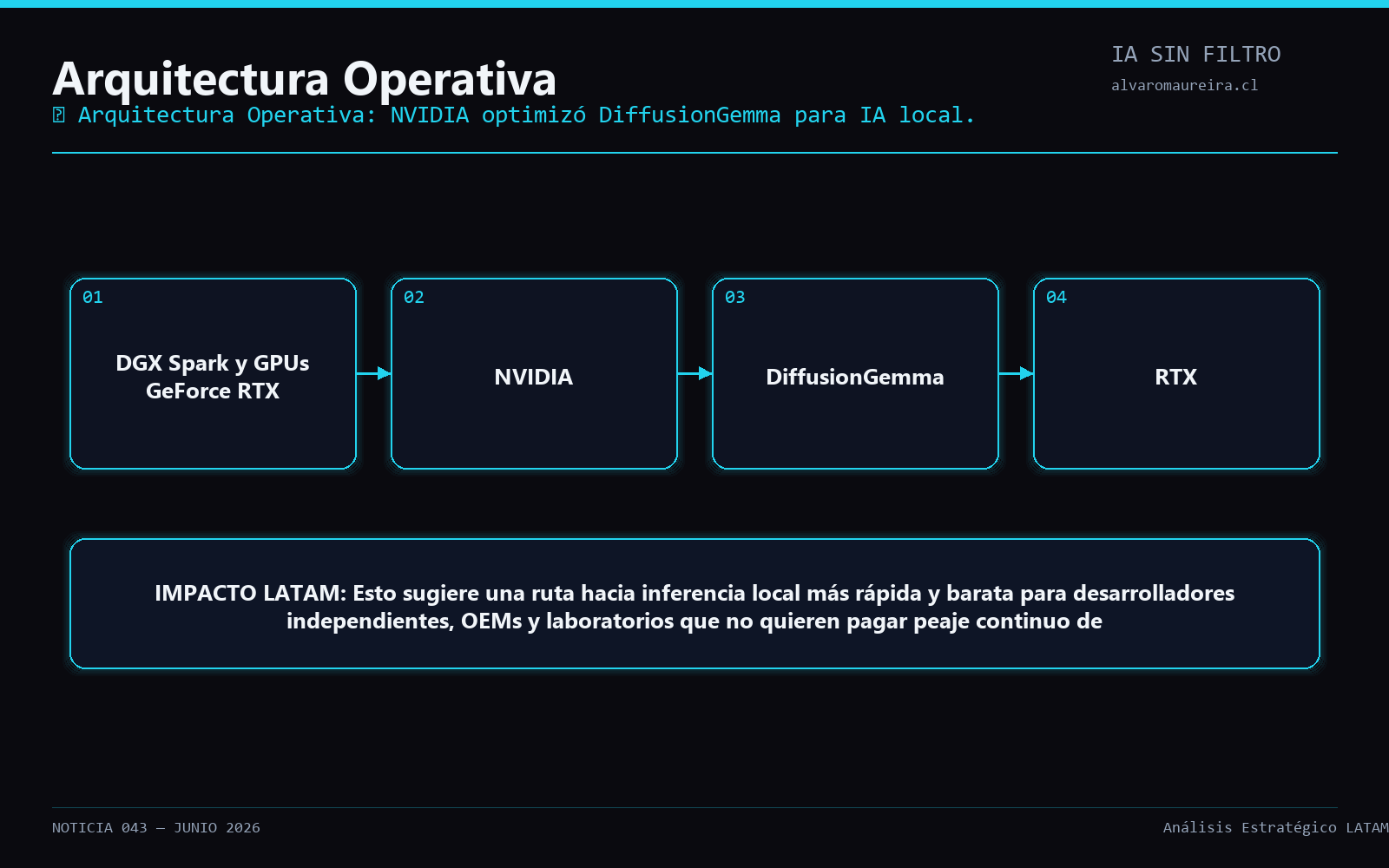
NVIDIA optimizó DiffusionGemma para IA local.. NVIDIA dijo que el modelo abierto DiffusionGemma genera texto en paralelo —no token a token— y fue optimizado para RTX PRO, DGX Spark y GPUs GeForce RTX.
✦ Arquitectura Operativa: NVIDIA optimizó DiffusionGemma para IA local.
Análisis del Acontecimiento y Contexto Tecnológico
NVIDIA dijo que el modelo abierto DiffusionGemma genera texto en paralelo —no token a token— y fue optimizado para RTX PRO, DGX Spark y GPUs GeForce RTX.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
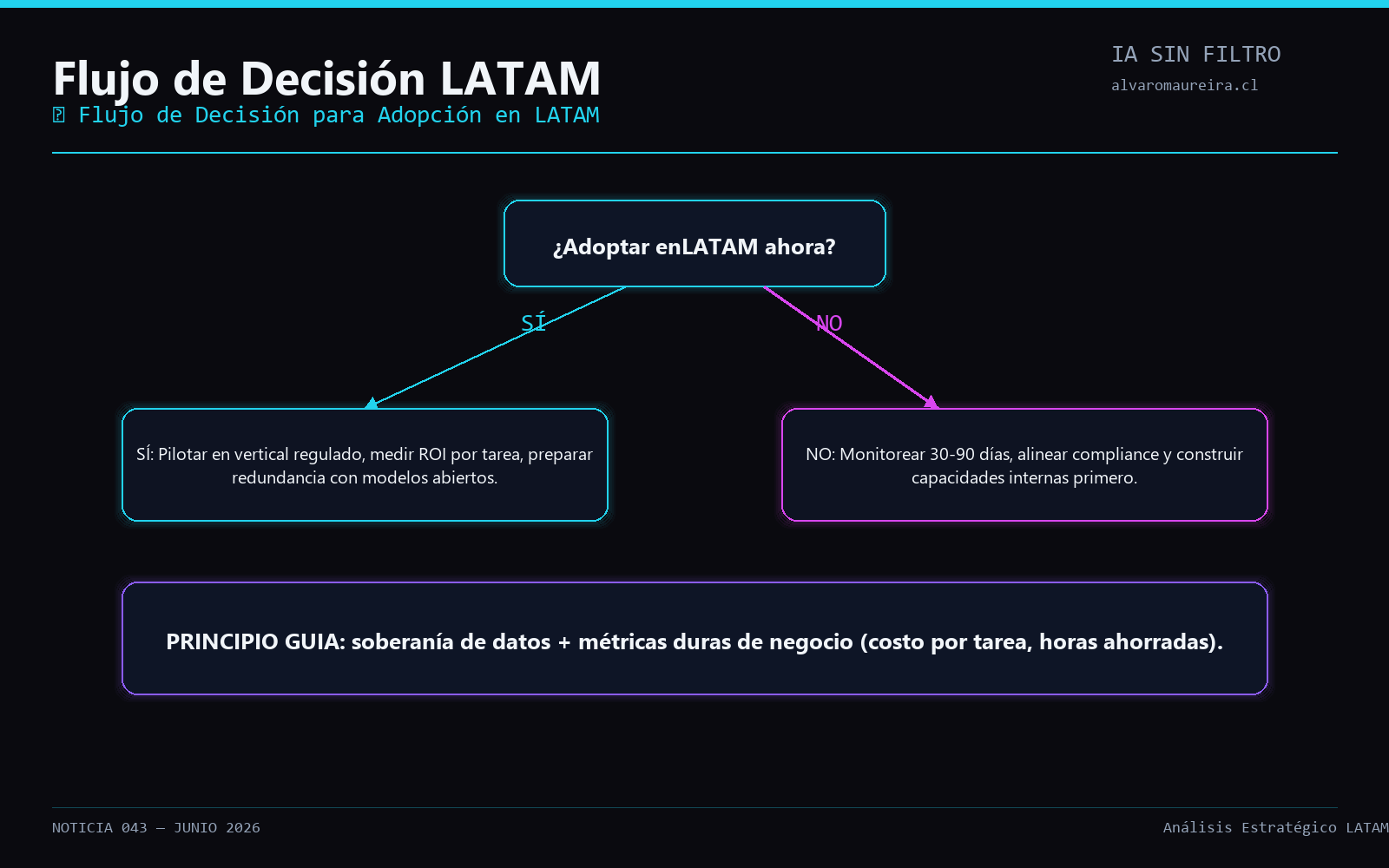
Esto sugiere una ruta hacia inferencia local más rápida y barata para desarrolladores independientes, OEMs y laboratorios que no quieren pagar peaje continuo de API.

✦ Mapa de Componentes y Actores Clave
✦ Flujo de Decisión para Adopción en LATAM
Preguntas Frecuentes
✦ ¿En qué consiste este anuncio?
NVIDIA dijo que el modelo abierto DiffusionGemma genera texto en paralelo —no token a token— y fue optimizado para RTX PRO, DGX Spark y GPUs GeForce RTX.
✦ ¿Qué impacto estratégico tiene para América Latina?
Esto sugiere una ruta hacia inferencia local más rápida y barata para desarrolladores independientes, OEMs y laboratorios que no quieren pagar peaje continuo de API.
✦ ¿Qué acción concreta pueden tomar las consultoras de LATAM?
Evaluéis pilotar la tecnología en un vertical regulado de la región (banca, salud o sector público), midiendo retorno en costo por tarea completada y preparando redundancia con modelos abiertos ante posibles restricciones de acceso.
Fuente original de referencia: NVIDIA Blog
Únete a la Comunidad Oficial de WhatsApp
Recibe notificaciones instantáneas de boletines tecnológicos de frontera, plantillas exclusivas y blueprints de automatizaciones Multi-Agente.

