
La frontera entre la nube y el hardware local acaba de desvanecerse. Ollama v0.30.6 despliega el poder de Gemma 4 mediante Quantization-Aware Training (QAT), permitiendo que modelos masivos de hasta 31B parámetros operen con una eficiencia quirúrgica en dispositivos de borde. Esta actualización no es un simple parche; es la infraestructura necesaria para que la IA generativa deje de ser un lujo de servidores remotos y se convierta en un activo local, privado y ultra veloz.
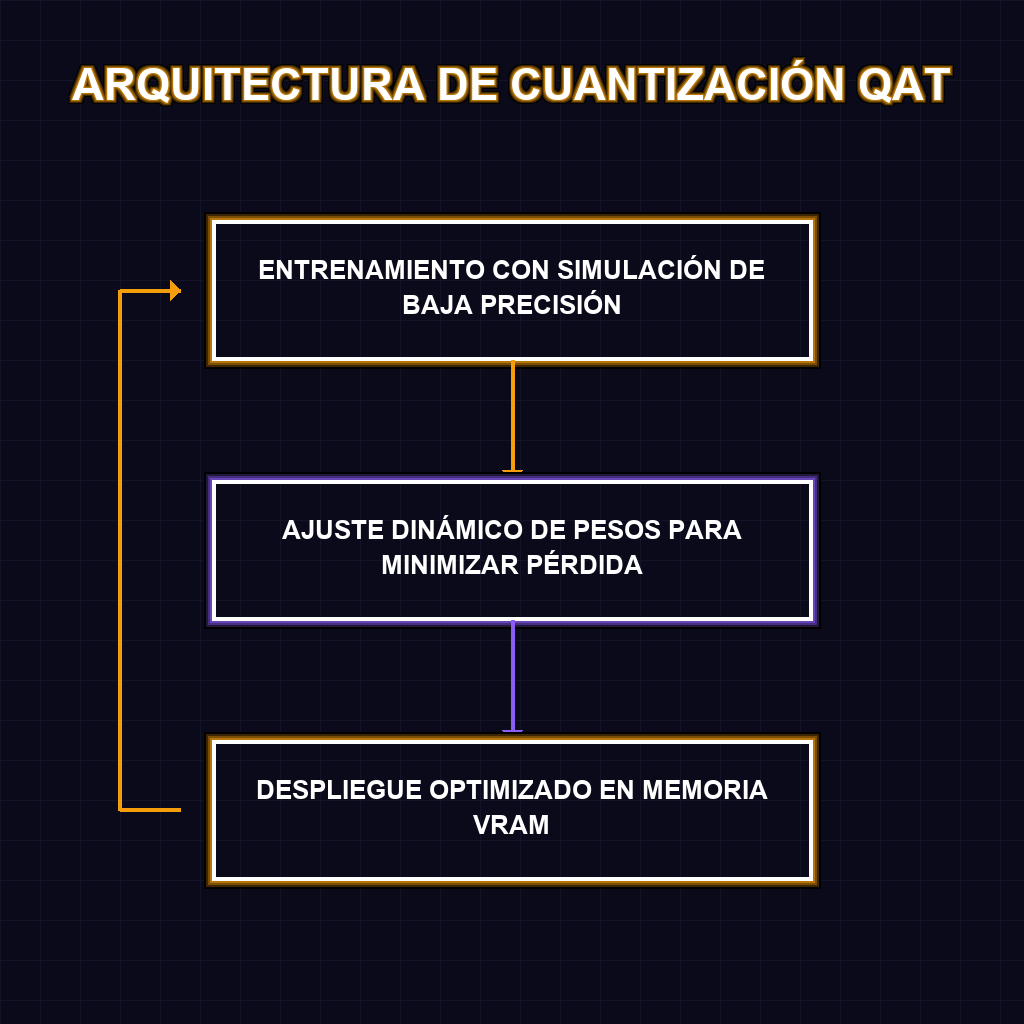
✦ ARQUITECTURA DE CUANTIZACIÓN QAT
Análisis del Acontecimiento y Contexto Tecnológico
La implementación de pesos QAT en Gemma 4 representa un salto cualitativo en la optimización de modelos. A diferencia de la cuantización tradicional, que reduce la precisión después del entrenamiento, el Quantization-Aware Training integra la pérdida de precisión durante el proceso de aprendizaje, permitiendo que el modelo se adapte a representaciones de menor bit sin sacrificar la coherencia semántica. Con opciones que van desde los 2B hasta los 31B, Ollama permite una granularidad sin precedentes, optimizando el uso de VRAM y permitiendo que hardware modesto ejecute razonamientos complejos que antes requerían clusters de GPUs industriales.
A largo plazo, estamos presenciando la consolidación de la Edge AI como el estándar operativo para la privacidad corporativa. La optimización de las capas de incrustación MLX para Apple Silicon y la integración con Oh My Pi sugieren un futuro donde la inferencia ocurre en el dispositivo del usuario final, eliminando la latencia de red y los costos recurrentes de API. Esta tendencia desplaza el valor desde quien posee el cómputo hacia quien posee la implementación eficiente, democratizando el acceso a modelos de frontera y permitiendo la creación de agentes autónomos que operan en total aislamiento y seguridad.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el ecosistema empresarial en Latinoamérica, donde la infraestructura de nube puede ser costosa y la conectividad inestable, esta actualización es un catalizador de competitividad. La capacidad de desplegar modelos de alta capacidad en hardware local reduce la barrera de entrada tecnológica y protege la soberanía de los datos.
- Independencia de Infraestructura: Reducción de la dependencia de proveedores de nube extranjeros y mitigación de costos por consumo de tokens.
- Soberanía de Datos Críticos: Implementación de IA en entornos locales para garantizar que la información sensible nunca salga del perímetro de la empresa.
- Optimización de Hardware Existente: Maximización del rendimiento en estaciones de trabajo Apple Silicon y dispositivos de borde, extendiendo la vida útil del hardware.
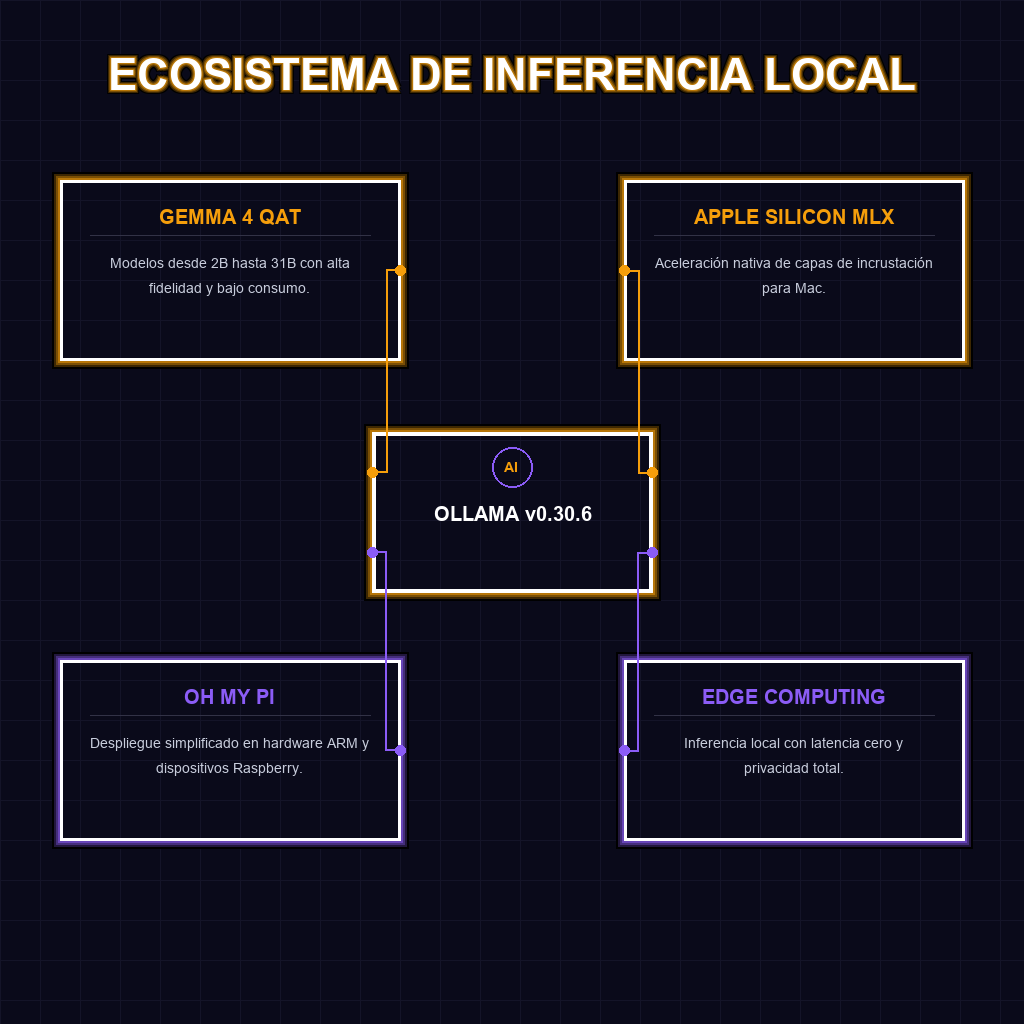
✦ ECOSISTEMA DE INFERENCIA LOCAL
✦ FLUJO DE DESPLIEGUE DE IA LOCAL
Preguntas Frecuentes
✦ ¿Qué es QAT y por qué es superior a la cuantización estándar?
El Quantization-Aware Training (QAT) es un proceso donde el modelo es entrenado simulando la pérdida de precisión. Esto permite que el modelo aprenda a compensar los errores de cuantización, resultando en una precisión mucho más cercana al modelo original de 32 bits que la cuantización post-entrenamiento tradicional.
✦ ¿Cómo beneficia la mejora de MLX a los usuarios de Mac?
MLX es el framework de Apple para aprendizaje automático. La optimización de las capas de incrustación permite que Ollama utilice la memoria unificada de los chips M1, M2 y M3 de manera más eficiente, reduciendo el tiempo de respuesta y permitiendo cargar modelos más grandes sin saturar el sistema.
✦ ¿Para qué sirve la integración ‘ollama launch omp’?
Esta función facilita la implementación de modelos de IA en entornos Oh My Pi, optimizando el despliegue en hardware basado en ARM. Es ideal para crear nodos de IA ligeros, servidores domésticos o dispositivos de automatización industrial que no requieren una GPU masiva.
Fuente original de referencia: Ollama GitHub Releases (vía AI Automation Library)
📥 Descarga el Recurso Gratuito
Accede a nuestro catálogo de agentes de IA empresariales autónomos, diseñados con arquitecturas de runtime robustas.

