
El monopolio del silicio propietario tiene sus días contados. OpenAI y AMD han fusionado su ingeniería para desplegar una nueva línea de aceleradores de inferencia de código abierto, diseñados para devorar modelos de lenguaje a escala de datacenter con un consumo energético reducido en un 50%. Equipados con controladores RISC-V personalizables, estos chips destruyen las barreras de entrada para proveedores de nube regionales, inaugurando una era de infraestructura autónoma y competitiva.
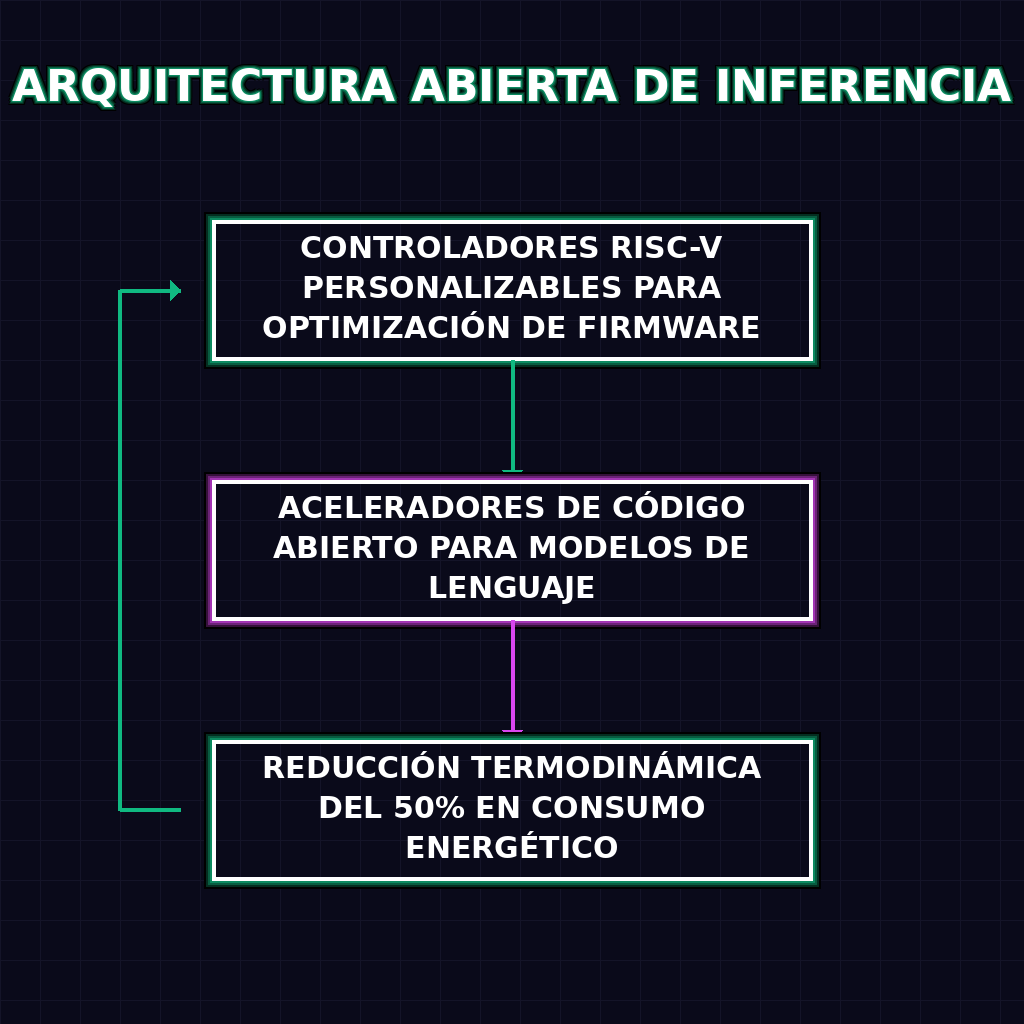
✦ ARQUITECTURA ABIERTA DE INFERENCIA
Análisis del Acontecimiento y Contexto Tecnológico
La convergencia entre el titán del software generativo y el gigante de silicio alternativo representa un ataque frontal a la arquitectura cerrada que ha asfixiado la innovación en infraestructura. Al integrar controladores basados en la arquitectura abierta RISC-V, estos aceleradores de inferencia permiten a los ingenieros de datos optimizar a nivel de firmware las rutinas de ejecución para LLMs, eliminando la sobrecarga computacional de las abstracciones propietarias. La promesa de una reducción del 50% en el consumo energético no es una simple métrica de marketing; es el resultado directo de eliminar las capas de software intermediario, permitiendo que las operaciones de multiplicación de matrices fluyan con una eficiencia termodinámica sin precedentes. Este movimiento descentraliza el poder de la optimización, entregándolo de vuelta a los arquitectos de centros de datos.
A largo plazo, la liberación del hardware de inferencia reescribirá la economía de la inteligencia artificial corporativa. Las cuotas de mercado de los ecosistemas propietarios colapsarán bajo el peso de sus propias licencias restrictivas, dando paso a un paradigma de nubes regionales altamente eficientes y especializadas. La inferencia de modelos de gran escala dejará de ser un servicio de lujo ofrecido por un oligopolio para convertirse en una utilidad básica, distribuida geográficamente y operada por proveedores locales que controlarán sus propios márgenes. Las empresas que dependen de la IA para sus operaciones críticas obtendrán soberanía computacional real, mitigando riesgos de bloqueo de proveedor y reduciendo drásticamente los costos operativos de despliegue continuo.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el ecosistema empresarial de LATAM, este avance tecnológico es la llave maestra para escapar del vasallaje computacional. Las telecomunicaciones y los proveedores de nube local han visto frustradas sus ambiciones de ofrecer IA como servicio debido a los márgenes abusivos y la escasez de hardware propietario. Con estos aceleradores de código abierto, la región puede construir infraestructura de clase mundial de forma autónoma, procesando datos dentro de sus propias fronteras y creando ecosistemas de IA rentables, soberanos y adaptados a la realidad del mercado hispanohablante.
- Soberanía de datos e infraestructura: Procesamiento local de LLMs sin depender de centros de datos extranjeros ni licencias restrictivas.
- Optimización de costos operativos: Reducción drástica del gasto en energía y hardware, democratizando el acceso a la inferencia de alta gama.
- Creación de ecosistemas de IA regional: Telecom y nube local pueden comercializar servicios de IA competitivos adaptados al español y contextos locales.
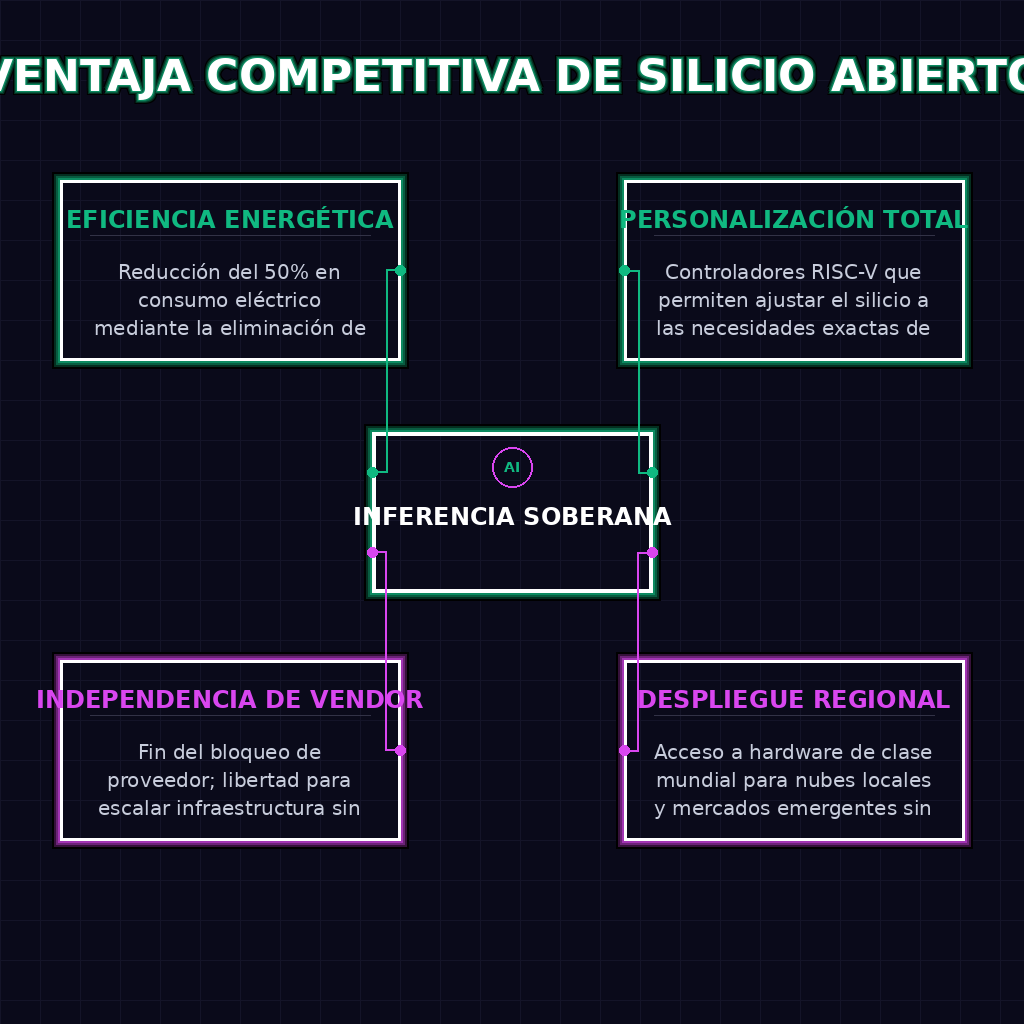
✦ VENTAJA COMPETITIVA DE SILICIO ABIERTO
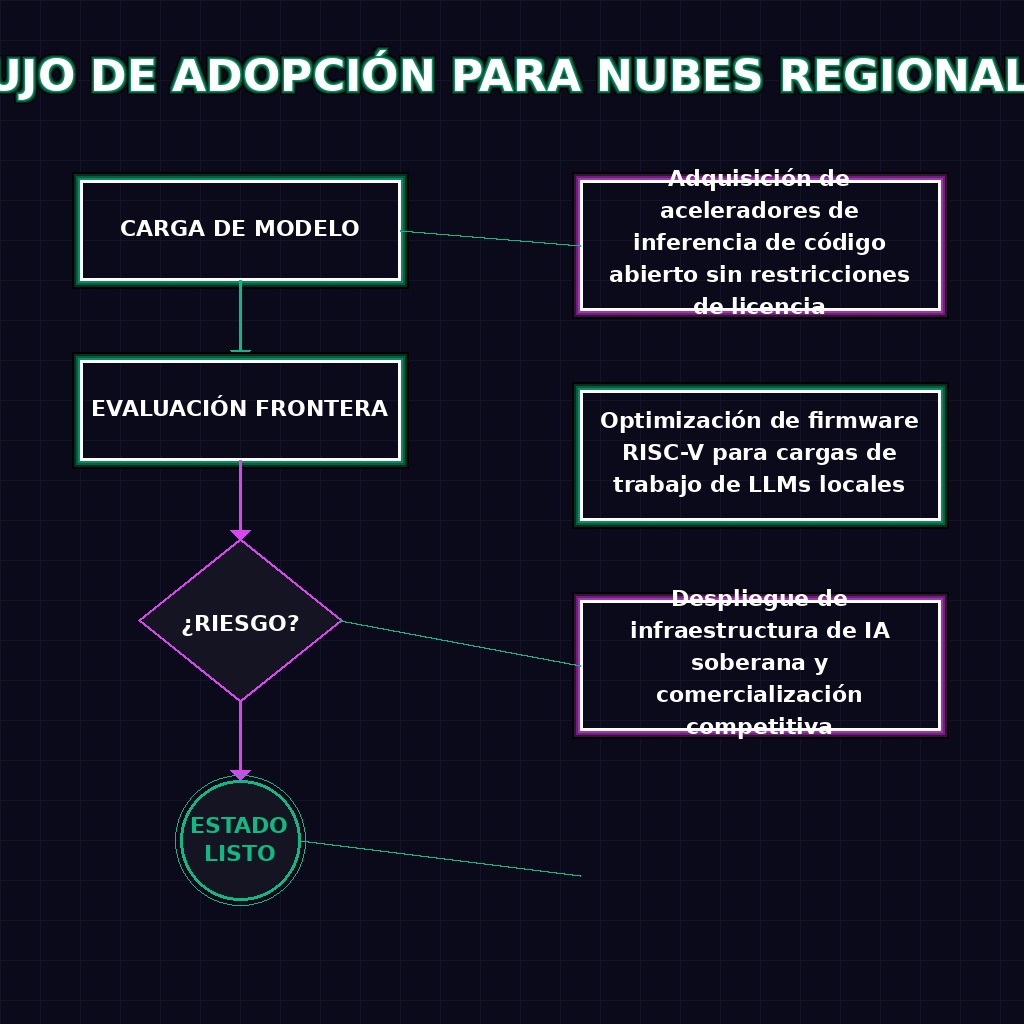
✦ FLUJO DE ADOPCIÓN PARA NUBES REGIONALES
Preguntas Frecuentes
✦ ¿Por qué el uso de controladores RISC-V es tan disruptivo en estos nuevos chips de inferencia?
RISC-V es una arquitectura de conjunto de instrucciones abierta, lo que significa que los desarrolladores no están limitados por las restricciones de licencias propietarias. Esto permite a los proveedores de centros de datos modificar y optimizar el firmware a nivel de hardware para tareas específicas de inferencia de LLMs, eliminando ineficiencias, reduciendo la latencia y logrando la reducción del 50% en consumo energético prometida.
✦ ¿Qué impacto real tiene la reducción del 50% en consumo energético para un centro de datos corporativo?
La inferencia de modelos de lenguaje a gran escala es extremadamente intensiva en energía. Reducir el consumo a la mitad no solo disminuye drásticamente los costos operativos de electricidad y refrigeración, sino que también permite una mayor densidad computacional por rack sin necesidad de rediseñar la infraestructura eléctrica del centro de datos, acelerando el retorno de inversión y mejorando la sostenibilidad.
✦ ¿Cómo beneficia específicamente a los proveedores de nube regional en LATAM este lanzamiento?
Históricamente, los proveedores locales han estado excluidos de la competencia en IA por la falta de acceso al hardware propietario dominante y sus altos costos. Estos chips de código abierto eliminan esa barrera de entrada, permitiendo a las empresas de telecomunicaciones y nube en LATAM construir su propia infraestructura de inferencia, mantener los datos dentro de las fronteras nacionales y ofrecer servicios de IA competitivos y rentables sin depender de monopolios extranjeros.
Fuente original de referencia: Reuters Technology
📥 Descarga el Recurso Gratuito
Prepara tus canales de venta, automatizaciones y aplicaciones móviles para el nuevo paradigma de agentes de voz impulsados por IA.

