
El Senado de México ha encendido el motor regulatorio de LATAM. Con votación unánime, se aprueba la Ley Federal de Inteligencia Artificial y Datos, un marco pionero que impone transparencia algorítmica, crea el Registro Nacional de Modelos de IA y revoluciona la economía creativa con los derechos de autor derivados. Las empresas tienen 18 meses para registrar sus sistemas operativos. México no solo regula el futuro, lo certifica, atrayendo capital extranjero y detonando un boom en plataformas de gestión de datos limpios.
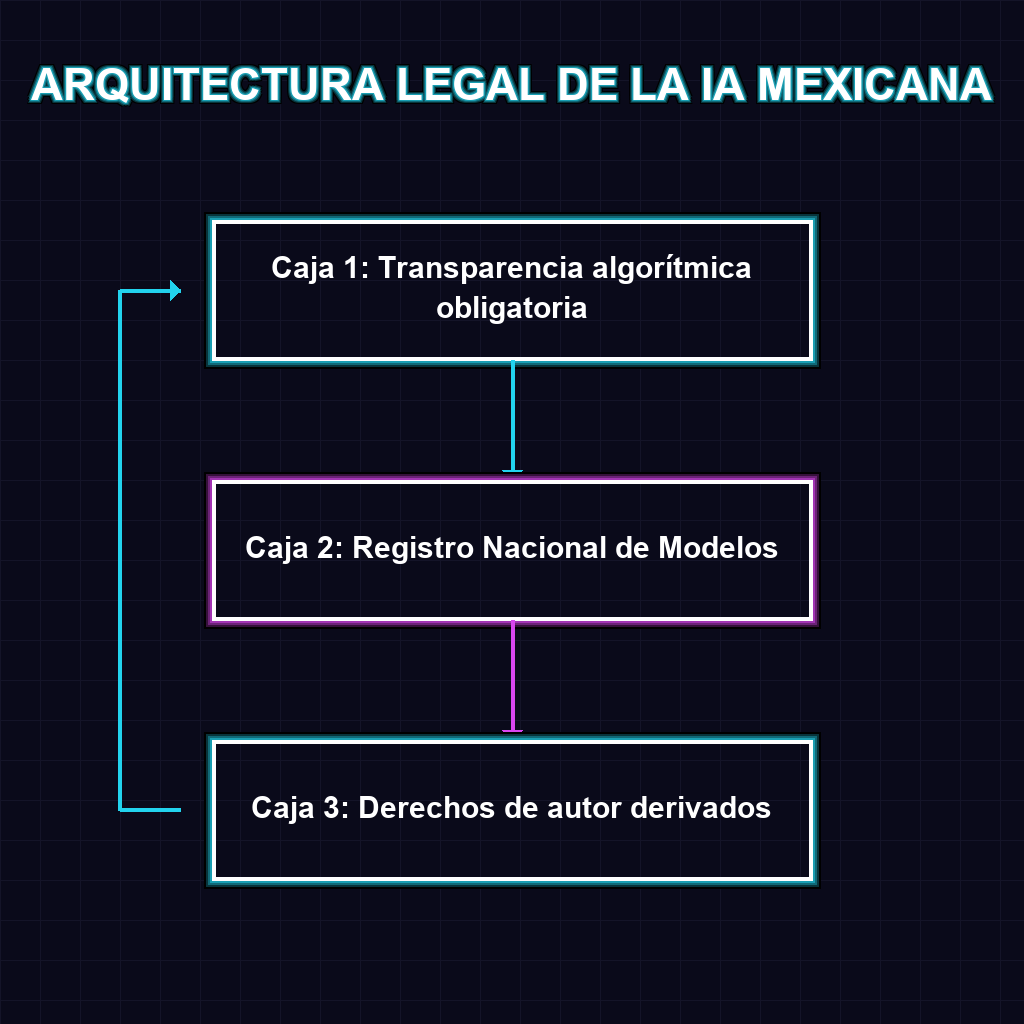
✦ ARQUITECTURA LEGAL DE LA IA MEXICANA
Análisis del Acontecimiento y Contexto Tecnológico
La aprobación de esta legislación no es un simple trámite burocrático; es una reconfiguración profunda de la topología empresarial y tecnológica en la región. El establecimiento de un Registro Nacional de Modelos de IA obliga a las corporaciones a dejar de operar en la opacidad algorítmica. En un ecosistema donde la ventaja competitiva dependía de la asimetría de la información y el scraping de datos sin restricciones, el Estado mexicano exige trazabilidad total sobre las fuentes de entrenamiento fundacional. Esto transforma la IA de una herramienta de caja negra a un activo auditado, donde la reproducibilidad y la transparencia de los pesos se vuelven obligatorias para operar en el mercado nacional. Las arquitecturas de datos deben adaptarse a un paradigma donde la ingesta de información requiere consentimiento, trazabilidad y compensación.
El concepto de derechos de autor derivados es la verdadera disrupción sistémica de esta ley. Al reconocer que los datos utilizados en el entrenamiento fundacional generan valor comercial, se establece un precedente que rompe con la explotación histórica del scraping masivo. A largo plazo, esto reescribe las reglas de la economía digital: los creadores de contenido y propietarios de datasets ahora poseen activos negociables y exigibles. Las plataformas tecnológicas se verán forzadas a diseñar arquitecturas de compensación automatizada, rastreando la influencia de cada dataset en las inferencias finales. Esta medida no solo frena el robo de propiedad intelectual, sino que cataliza el surgimiento de un mercado secundario de datos certificados, donde la calidad y la legalidad del dataset premium superarán en valor a los modelos entrenados con datos contaminados o ilegales.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el ecosistema empresarial de LATAM, esta ley es la señal de alineación que el capital global estaba esperando. México opera como el primer mercado de tamaño significativo que ofrece certidumbre jurídica integral para la inversión extranjera en infraestructura de inteligencia artificial. Mientras otras jurisdicciones de la región navegan en la ambigüedad legal, las empresas que instalen sus centros de datos y operaciones en México obtendrán una ventaja competitiva brutal: la legitimidad regulatoria. La demanda inmediata de plataformas de gestión de derechos de autor y curaduría de datasets limpios creará un subsector tecnológico próspero, convirtiendo a la región en un hub de innovación en gobernanza de datos.
- Las empresas deben auditar sus pipelines de datos inmediatamente para identificar y mitigar riesgos de propiedad intelectual antes de la ventana de 18 meses.
- El desarrollo e implementación de plataformas de gestión de derechos de autor derivados se convierte en el sector de mayor crecimiento y rentabilidad en la región.
- Operar bajo el paraguas regulatorio mexicano otorga un sello de confianza premium para atraer capital de riesgo global e inversión en infraestructura de IA.
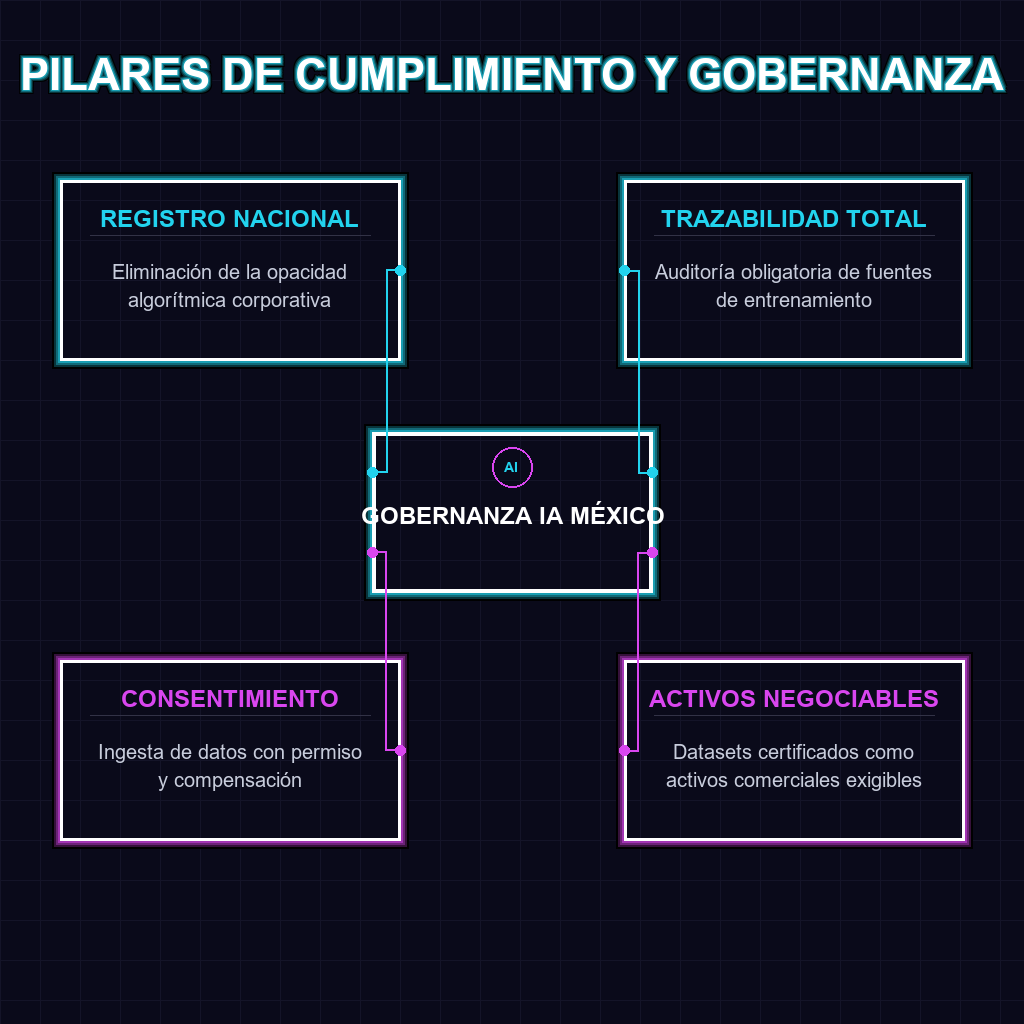
✦ PILARES DE CUMPLIMIENTO Y GOBERNANZA
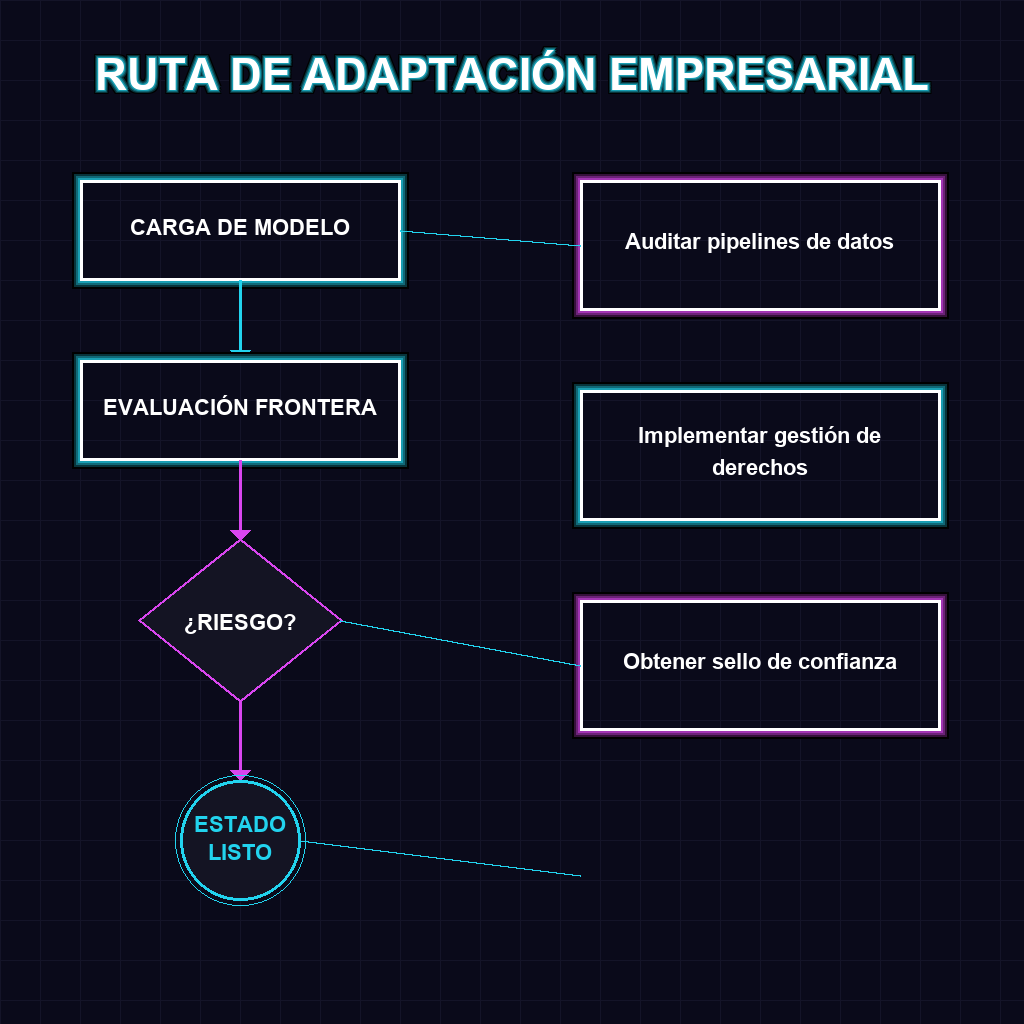
✦ RUTA DE ADAPTACIÓN EMPRESARIAL
Preguntas Frecuentes
✦ ¿Qué ocurre si mi empresa no registra sus modelos de IA en el plazo de 18 meses?
La legislación es clara y pragmática: la falta de registro dentro de la ventana de adaptación de 18 meses resultará en la prohibición operativa del sistema en territorio mexicano, además de multas severas por operar en la clandestinidad algorítmica. El registro no es opcional, es el pasaporte para operar legalmente y acceder a los beneficios de la certidumbre jurídica que el mercado exige.
✦ ¿Cómo se calcula y distribuye la compensación por los derechos de autor derivados?
La ley establece que los modelos deben implementar mecanismos de trazabilidad para identificar la influencia de los datasets de entrenamiento en las inferencias comerciales. La compensación se calcula en función del valor económico generado y la proporción de los datos del creador en el resultado final. Las plataformas de gestión de derechos automatizarán estos micropagos, asegurando que los creadores reciban regalías sin fricción.
✦ ¿Esta ley aplica solo a empresas mexicanas o también a plataformas extranjeras que operan en el país?
La jurisdicción de la Ley Federal de Inteligencia Artificial y Datos es territorial y extraterritorial en sus efectos digitales. Cualquier plataforma, sea nacional o extranjera, que ofrezca servicios de IA a usuarios en México o que procese datos de residentes mexicanos para entrenamiento, debe cumplir con el registro federal y las obligaciones de derechos de autor derivados. No hay refugio legal para la extracción de datos en la opacidad.
Fuente original de referencia: GobMX Senado
📥 Descarga el Recurso Gratuito
Accede a nuestro catálogo de agentes de IA empresariales autónomos, diseñados con arquitecturas de runtime robustas.

