
La era de la opacidad en los costos de IA ha terminado. xAI ha desplegado una actualización quirúrgica en la estructura de precios de Grok, transformando la incertidumbre financiera en una hoja de ruta técnica precisa. Para los arquitectos de soluciones y CEOs, esto no es solo una lista de precios, sino la infraestructura necesaria para escalar agentes autónomos con un control absoluto sobre el gasto operativo en el ecosistema de inteligencia artificial generativa.
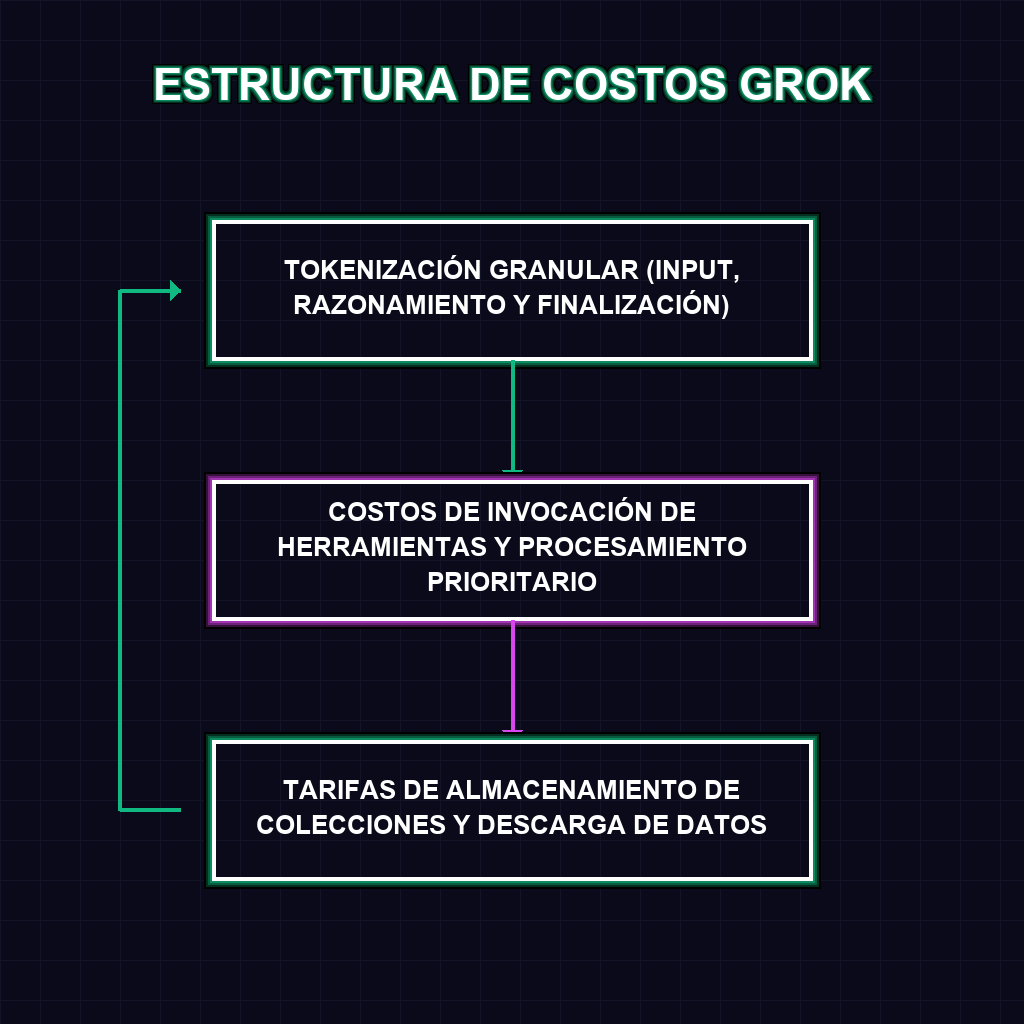
✦ ESTRUCTURA DE COSTOS GROK
Análisis del Acontecimiento y Contexto Tecnológico
La introducción de costos diferenciados para tokens de razonamiento y tokens de caché marca un hito en la madurez de los Modelos de Lenguaje Extensos (LLMs). Al desglosar el costo de la reflexión del modelo frente a la generación final, xAI permite a los desarrolladores optimizar la profundidad del pensamiento computacional según la complejidad de la tarea. Esta granularidad técnica es fundamental para implementar flujos de trabajo donde la precisión es crítica, permitiendo que el procesamiento prioritario y la invocación de herramientas se conviertan en variables ajustables para maximizar el ROI tecnológico.
A largo plazo, este movimiento posiciona a Grok como una alternativa pragmática y transparente frente a la competencia. La capacidad de presupuestar el almacenamiento de colecciones y las descargas de datos sugiere que xAI está pivotando hacia un modelo de IA como Infraestructura (AIaaS), donde el modelo no es solo un chat, sino una base de datos dinámica y un motor de ejecución. Las empresas que dominen la gestión de estos costos ahora tendrán una ventaja competitiva disruptiva, reduciendo el desperdicio de tokens y optimizando la latencia mediante el uso estratégico de la memoria caché.
Ángulo de Negocio y Oportunidad Estratégica para LATAM
Para el ecosistema empresarial en Latinoamérica, donde la eficiencia del capital es la regla de oro, esta transparencia representa una oportunidad táctica para desplazar soluciones costosas por arquitecturas optimizadas y escalables.
- Optimización de OpEx: Implementar estrategias de caché para reducir la dependencia de tokens de entrada costosos en mercados con presupuestos ajustados.
- Arquitecturas Híbridas: Utilizar el procesamiento prioritario solo para tareas críticas de cliente, delegando procesos internos a capas de costo estándar.
- Planificación Financiera Predictiva: Migrar de modelos de pago imprevistos a presupuestos basados en el volumen real de tokens de razonamiento y almacenamiento.
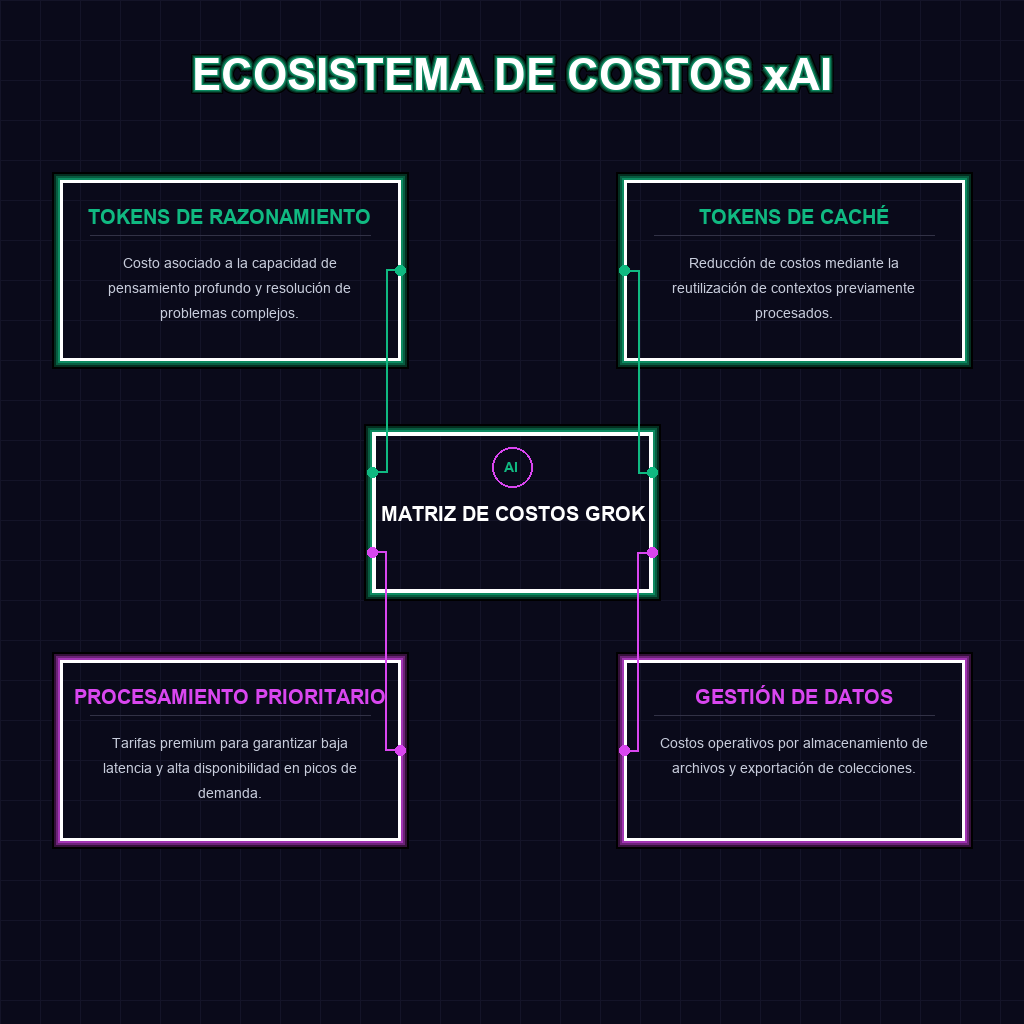
✦ ECOSISTEMA DE COSTOS xAI
✦ FLUJO DE OPTIMIZACIÓN OPERATIVA
Preguntas Frecuentes
✦ ¿Qué son los tokens de razonamiento y por qué tienen un costo distinto?
Los tokens de razonamiento representan el proceso interno de pensamiento del modelo antes de generar la respuesta final. Al cobrar estos tokens por separado, xAI permite que las empresas decidan cuánta capacidad de análisis profundo requieren para cada tarea, evitando pagar por razonamiento complejo en respuestas simples.
✦ ¿Cómo beneficia la introducción de tokens de caché a las empresas?
Los tokens de caché permiten almacenar fragmentos de prompts o contextos extensos que se repiten frecuentemente. Esto reduce drásticamente el costo de los tokens de entrada y acelera el tiempo de respuesta, ya que el modelo no tiene que procesar la misma información desde cero en cada solicitud.
✦ ¿En qué impacta el costo de almacenamiento de colecciones?
Impacta directamente en la creación de bases de conocimiento personalizadas. Al detallar el costo de almacenamiento y descarga, xAI permite que las empresas calculen el costo total de propiedad (TCO) de mantener sus propios datasets integrados en el modelo Grok para aplicaciones RAG (Retrieval-Augmented Generation).
Fuente original de referencia: xAI Docs
📥 Descarga el Recurso Gratuito
Prepara tus canales de venta, automatizaciones y aplicaciones móviles para el nuevo paradigma de agentes de voz impulsados por IA.

